
This is my first English blog. I wish to improve my English through writing English blogs. Vuzzer is the first Application-aware fuuzer that I’ve encountered. It uses the mutation guided by taint analysis to replace the AFL-like blind mutation, which make test cases can execute more basic block with fewer mutations.
Introduction
Firstly, The paper introduces the defects of the traditional guided fuzzer and symbolic execution fuzzer.
AFL is used as the representation of the traditional guided fuzzer in paper. AFL uses a kind of evolutionary algorithm to produce suitable test cases. Such algorithm combines and mutates selected test cases to produce new test cases. All the new test cases will be used as inputs to test the target program and then the algorithm will assess how good a new test case is according to its running state. Specifically, AFL will remain any new test cases which discover the new path. Finally, the test case will be appended to the corpus. As the paper saying, this selection method can not select the most appropriate one from all test cases produced by AFL. Moreover, the mutation of the algorithm is randomly and blindly which can't effectively produce proper test cases. To make the mutation more effectively, paper suggest that there are two questions must be answered:
- where to mutate? (which offset in test case)
- what value should be used for the mutation?
AFL can’t answer these questions at all because of its blind mutation strategy. Its Mutation strategy is designed to produce a large number of test cases in hope of discovering the new path or triggering some crashes. This is a very slow strategy and relies heavily on luck. In order to increasing the reliability of the mutation strategy of AFL, paper proposes that we can collect the information through the dynamic and static analysis to answer the two questions above.
In this direction, the symbolic and concolic execution fuzzer are introduced to us. ([TODO]: I haven’t read the paper about these two kinds of fuzzer so I don’t know how they work.) The symbolic execution will help AFL to explore the new paths when it was stuck. However, in spite of this progress, the application of the symbol execution will decrease the scalability of AFL according to the paper.
To solve the problem above, paper present VUzzer, a kind of application-aware evolutionary fuzzer with high scalability and efficiency. It use lightweight dynamic and static analysis to replace the symbolic execution to guide the mutation while ensuring the scalability. Vuzzer uses control-flow information to prioritize the deep paths and deprioritize the shallow paths and it also uses the data-flow information to determine where and how to mutate the test cases. And the following part will introduce the design and implementation of the VUzzer.
Background
This section will introduce some pitfalls encountered when we use AFL to test program.
All the pitfalls are related to complex code structures. Therefore, paper use a code snippet to illuminate these pitfalls to us.

- Magic bytes(line 11)
- Deeper execution(line 15): It will spend a long time for AFL to guess the right offset and combination of the bytes. Thus the majority of the test case will fall into the “else” branch. This means that AFL will prefer exploring the “else” branch rather than the “if” branch(because it indeed finds new path in “else” branch) and this will make it hard for AFL to find the bug in the “if” branch.
- Markers(line 17): A comparison of entire string instead of separated char. It’s very hard for AFL to generate such consecutive bytes to take right branch. There is a more detailed explanation.
- nested conditions(line 17): For AFL, every path has the same importance while some path are more difficult to reach than others. It means that the majority of test cases produced by AFL will be used to explore the easy paths while only a little test cases can reach the hard paths. In terms of nested conditions, this makes that the bugs in deep branches are hard to be detected. It is obvious that the balance strategy should be adjusted. AFL should prioritize efforts to the deep paths based on the collected control flow information.
Overview
The following picture displaces the workflow and composition of the VUzzer.
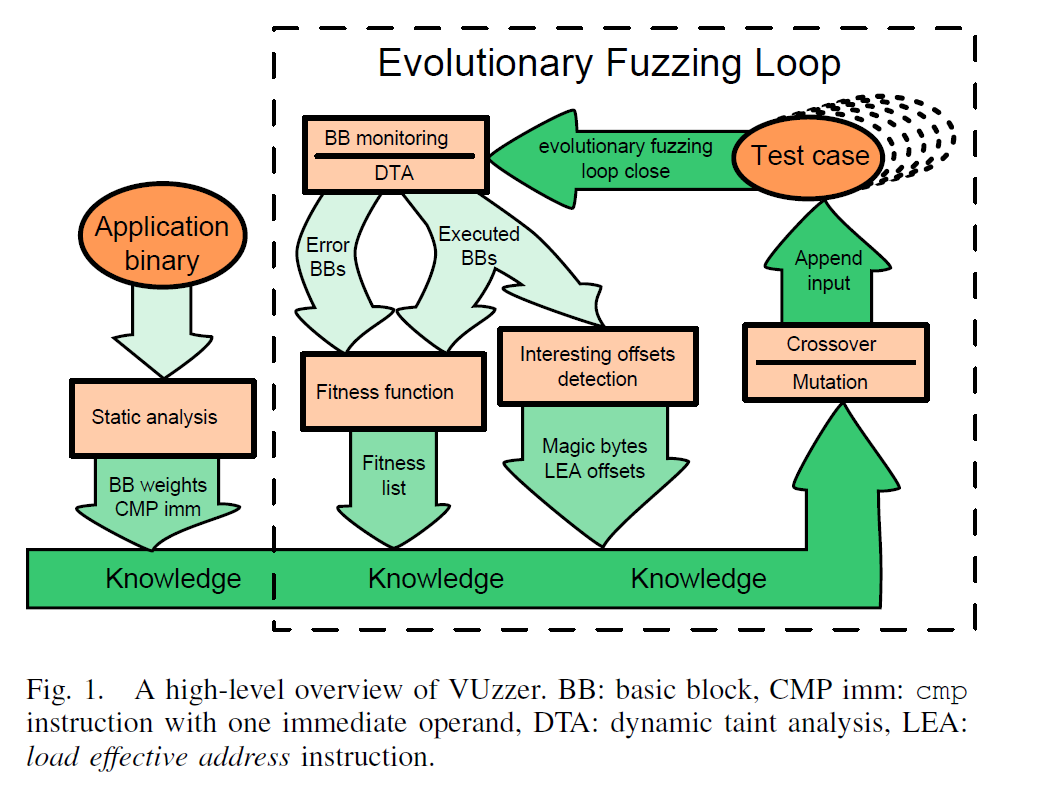
The VUzzer has the same fuzzing loop just as AFL. The difference between the two fuzzer is that VUzzer uses the binary analysis technique to make fuzzing loop smarter. The “smarter” means that VUzzer has better mutation strategies and test case choosing algorithms which will be discussed with much more detail blow.
The binary analysis module of VUzzer is made up of two parts according to the picture above, the static part on left and the dynamic part on the right. There are some differences between these two parts:
- Static analysis: The static analysis part dose not get involved in the fuzzing loop as we can see from the picture. Actually, It is performed just before the fuzzing loop to gather the information, for the whole process of the fuzzing loop.
- Dynamic analysis: The dynamic analysis is performed simultaneously with fuzzing loop. It gathers the runtime information and feed it to the mutation algorithm to produce the next generation of test cases. Moreover, VUzzer will also use this runtime information to determine which test case will be used for the next fuzzing test.
The next question we will discuss about is that What information should be gathered by binary analysis to guide the fuzzing loop?. VUzzer uses three kinds of features of application as the mutation guidance.
Data-flow feature: The Data-flow feature is that how input data are propagated in the program during the runtime.
taint traces: VUzzer uses the dynamic taint analysis(DTA) to get this feature to confirm which bytes in the input data can influence the control flow and then it can only change these bytes to change control flow. This will make mutation much more effective because of decrease of unuseful mutation. This can be achieved by instrumenting all
cmpinstruction with pin.index bytes identification: Moreover, VUzzer also uses DTA to identify the bytes which are used as the index in program by instrumenting the
leainstruction and checking which bytes of input taint the index operand oflea.magic bytes identification: Magic bytes are the sequence of bytes with the fixed content and the fixed position in the file format. Magic bytes always serve as the flag to indicate the type of file format. Therefore we can increase the reliability of produced test cases by identifying all the magic bytes.
Control-flow feature: The control-flow feature include execution depth of an individual basic block, the edge coverage of execution and all error handler basic blocks, respectively.
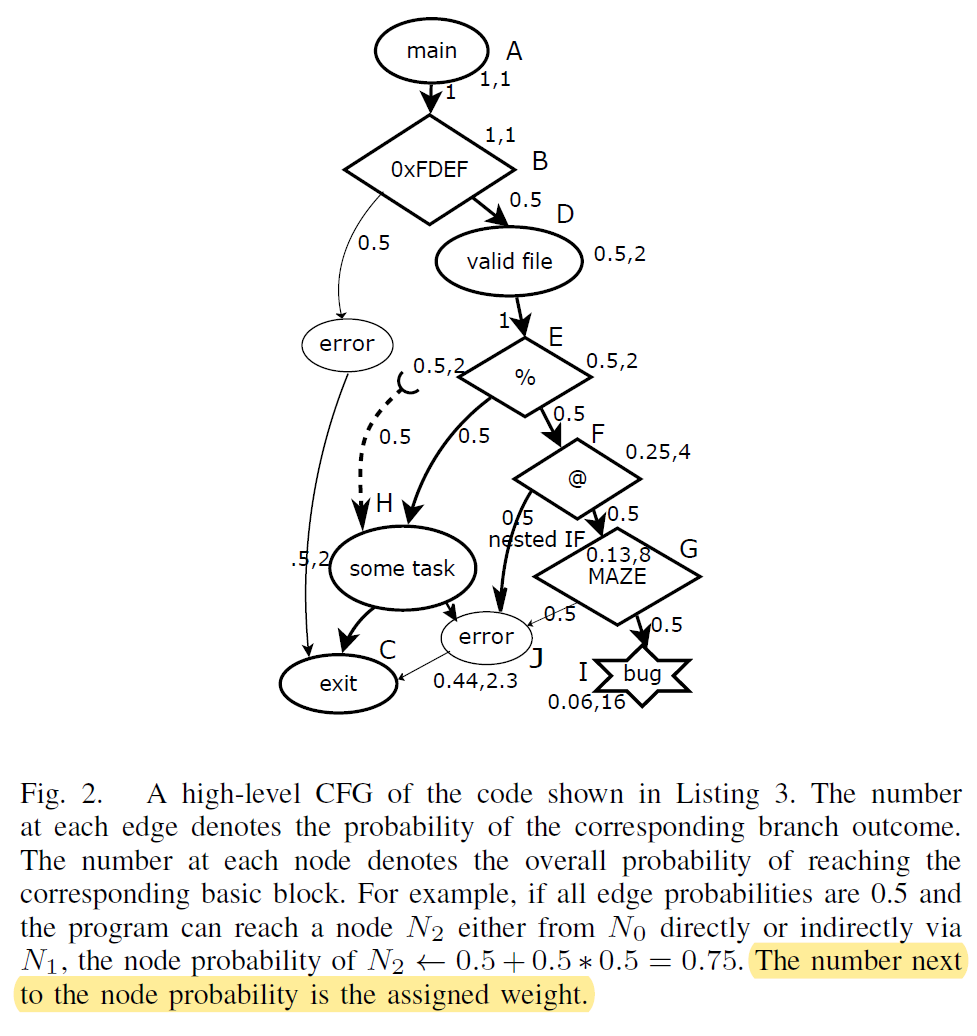
The depth is used to calculate the weight of the basic block. Basically, the deeper the basic block is, the bigger weight it will have and the test case with the biggest weight will be object of the next mutation. The following picture displaces an example.
![image-20221026154536535]()
The edge coverage is used to detect the error handler and determine whether there is a new edge found.
Error handler blocks are always not interesting. Therefore, we can skip test cases that execute error handler blocks by identifying these blocks.
other features: Immediate operands of the
cmpinstruction and constant arguments of the string comparison function such as magic number and flags will also be gathered during the static analysis.
All these features will be collected during the static or dynamic analysis. The following section will talk about how to collect this information and how fuzzing loop works.
design and implementation
This section will first talk about the works of the static and dynamic analysis and then discuss the fuzzing loop.
static analysis
Static analysis are responsible for collect following features of program:
- key word of program
- weight of basic block
During the static analysis, VUzzer will apply a lightweight intraprocedural binary code scan to obtain the constant operands of `cmp` instructions and constant arguments of the string comparison functions just like `srtcmp()`. I call it keyword indentification. For the code snippet in the Listing3, it can produce a list \(L_{imm}\) of byte sequences just like {0xFE, 0xFD, %, @, MAZE}. This list can be used in the mutation of whole fuzzing loop.
Moreover, there is also a basic block(BB) weight calculation data-flow analysis during the static analysis. Paper defines a intraprocedural fixed point iteration algorithm to compute the probability \(prob(b)\) of each BB \(b\) being executed. In short terms, the basic principle of this algorithm is that, for a given BB, every branch on the path from root to itself will decrease the probability of this BB being executed. After calculating the \(prob(b)\) of each BB, the \(weight(b)\) is equal to the reciprocal of the \(Prob(b)\). This means that a BB will has a bigger weight if it has a lower frequency to be executed. In the fuzzing loop, VUzzer will use the \(weight(b)\) to calculate the score of the test case, and the score will be used to determine the order which test cases are fuzzed in.
dynamic analysis
Dynamic analysis responsible for collect following features of program:
- taint traces
- error handler detection
- magic bytes detection
- the number of executed error handler BB
- code coverage and BB execution frequency
There are also several jobs during the dynamic analysis.
Firstly, It will employ the Dynamic Taint Analysis(DTA) to trace every cmp and lea instruction. Taint traces will not only be used to instruct which byte should be mutated but also will be used in magic bytes detection. For a instruction——cmp r0, 0XEF , 0xEF will be identified as a magic number if register r0 are always tainted by the byte with same offset in every execution.
Secondly, It will apply a error handler detection to count the number of executed error handler BB. This number will be used with weight of BB to calculate the score of the test cases. Just like AFL, VUzzer also needs a set of valid test case as the initial corpus. Test cases in this corpus will be executed before the fuzzing loop and VUzzer will collect all the BB executed by these test cases. Because these are all valid test cases, all these collected BB will not include the error handler code. Therefore, the BB which are not in this set will be the error handler BB.
As paper saying, just one time error handler detection can not discover all the handler so it design a incremental handler detection algorithm. The algorithm classify a basic block b as a handler block if this BB be executed by 90% test cases but is not included in the valid BB set.
Thirdly, there will also be module to count the edge coverage and the BB execution frequency just like AFL.(I don’t get a clear understanding of the dynamic analysis process after reading this paper so I think that reading the source code of the fuzzer would help.)
fuzzing loop
Before the main loop starts, VUzzer will apply a static analysis on the target program to collect imm operands and assign the weight to every BB. Then, it will execute the program with a set of test cases to collect the common running characteristic of valid test cases which will be used by the error handler and magic byte detection.
Then, the main fuzzing loop will begin. The following Algorithm describes this process:

Firstly, VUzzer will randomly select two parents from the ROOT set. The ROOT set is formed by initial corpus, tainted test cases and test cases with high fitness score.
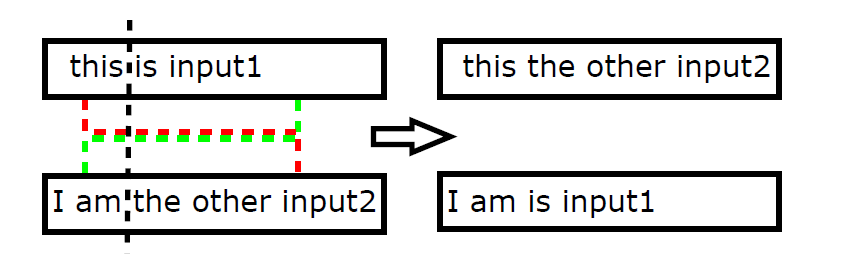
Then, the two parents will be recombined. The recombination process is just like AFL and there is an example:
![image-20221028144707511]()
After recombining, these two test cases will be further mutated. The mutation strategy will apply several steps to fully mutate the test cases:
- step 1: Randomly select tainted offsets from the set \(Other\)(\(Other\) set is the set which include all the tainted offsets which can influence
cmpinstruction but are not magic bytes place holder) and insert strings at these offsets. The inserted strings are selected from the constant operand ofcmpinstructions and string comparison functions . - Step 2: Randomly select offsets from the set \(L_{lea}\) (The offset of bytes which can taint the
leainstructions will be included in this set.)and mutate such offsets in the string from Step 1 by replacing them with interesting integer values, such as, 0,MAX UINT, negative numbers. - Step 3: For all the tainted
cmpinstructions for the parent input, if the values of op1 != op2, replace the op1 value at the tainted offset in the string from Step 2 with the value of op2 or else with a fixed probability replace the tainted byte by a random sequence of bytes. - Step 4: Place the magic bytes at the corresponding offsets as determined by our magic-byte detector.
As we can see, the mutation is not blind and it guided by features of program.
- step 1: Randomly select tainted offsets from the set \(Other\)(\(Other\) set is the set which include all the tainted offsets which can influence
Then VUzzer will execute the application with these two test cases. If there is a test case execute a new BB, it will be tainted and use DTA to collect the taint trace by overseeing the data-flow features of application.
After execution, there will be a fitness function to calculate the score, the weight of test cases actually, for the test case according to the running state. Specifically, the score is actually the sum of weight of all executed BB then minus the influence of the error handler BB. This calculation method will make test case which can execute more deep BB have more chances to be tested and produce more descendant.Then it will return to first step to choose parents.
conclusion
Using features of application to guide the mutation is a wonderful idea which I’ve never thought before. However, I think that the mutation strategy of VUzzer considers too much about the mutation which can influence the control-flow of the target program while it ignore the mutation strategy used by AFL which change the data properties of test case. I know that it is very important for test case to execute as many as basic blocks but the triggering of bug will also need the specific data conditions. I think we can combine them together to get a better performance.