
background
直接跳过论文最开始对于浏览器安全和JavaScript引擎安全的背景介绍。
Fuzzing Basic
现在常用的fuzz技术可以被分成两类:
- 基于生成的fuzz(Generative Fuzzing):在生成测试用例之前,必须向fuzzer提供一组语法规则来定义产生样本的格式。fuzzer将从一个”根产生式”开始,通过随机选择产生式进行扩展,最终得到一个不含非终结符的输出作为测试样本。
- 优点:因为所有的测试样本都是根据预定义的语法产生的,所以测试样本在语法上一定是有效的。
- 缺点:因为生成的样本没有经过某种形式的代码模拟,所以这些生成的样本在语义上很可能是无效的。比如说有可能出现变量还未定义就被使用的情况,但是这些情况在语法上是有效的。
- 基于变异的fuzz(Mutation-based Fuzzing): 基于变异的fuzzer需要一组已知行为良好的测试用例作为输入,然后fuzzer将在这些测试用例上进行随机的变异,变异后的结果将作为新测试用例被输入到程序中。在这样的设计思路下,基于变异的fuzz是否能成功和提供的输入测试用例有很大的关系。
- 缺点:将基于变异的fuzz应用到JavaScript引擎上需要克服的困难是如何设计变异来产生有效的测试用例,常规的变异方法例如:bit位反转、随机字符插入、随机字符串删除,很难产生有效的测试用例,意味着这些测试用例往往在词法分析或者语法分析阶段就会导致引擎停止工作,无法对引擎的内部结构进行测试。
- 优点:可以很好的配合后面所提到的guided fuzzing。
对于基于变异的fuzz如何设计变异以产生有效的测试用例,论文介绍了一种思路是在AST上进行变异。在初始的测试用例所生成的AST上进行变异,这样所生成的新测试用例在语法上肯定是正确的,但是在语义的正确性就不能得到保证,还是可能出现变量先使用后定义的情况。对于这样的问题也有相应的解决方法:
- 只对AST进行插入变异,且保证AST中插入的子树是其他测试用例的有效部分,这样就保证了变异后的测试用例在语义上是有效的。
- 另外一种方法就是使用try_catch块包裹住每个语句,这样一个语句的错误不会导致引擎的退出。
Guided Fuzzing
文章将guided fuzzing当做上面basic fuzz的扩展。其中基于变异的fuzz可以更好的配合Guided fuzz进行工作:fuzzer对输入的测试用例进行变异,并将变异后生成的测试用例喂给目标测试程序,如果得到了”好”的反馈,那么这个测试用例将被加入到变异队列中,在之后的测试中被继续变异,否则这个变异后的测试用例将被舍弃。
下面是文章中给出的是基于变异guided fuzzing算法的伪代码:

为了使guided fuzz能够工作的更加高效,对fuzzer的设计有下面两个要求:
- 所设计的变异规则首先要保证是有意义的(生成的测试用例在语法上是有效的)。另外,变异规则还需要在能够保留样本原有特性的情况下,对样本的语义进行改变,我觉得言外之意就是变异对样本的改变不能是很大尺度的。
- 另外fuzzer需要一个用来描述程序测试情况的指标。在guided fuzzer中广泛使用的指标是edge coverage,如果一个测试用例可以使程序在执行过程中覆盖到控制流图中之前没有覆盖到或者不经常覆盖到的边,那么fuzzer将获得一个积极的反馈,表示这个样本是我们所感兴趣的。edge coverage的优点就在于它可以用来描述不同的程序执行状态,但是不会导致路径爆炸等等问题。
在满足上面两个要求的情况下,guided fuzzer所生成的测试用例将在保证有效的前提下越来越复杂。
Analysis
那么最终论文实现了一个什么样的fuzzer,并且都有哪些需求呢?
Goal of the work
为了能够在JavaScript引擎中发现更多漏洞,fuzzer所生成的测试用例需要能够覆盖并测试到JavaScript引擎足够多的逻辑。这个正是guided fuzzing所擅长的领域。除此之外,通过调整guided fuzzing计算edge coverage的策略:比如只统计JavaScript引擎的某一个组成部分的edge coverage,所生成的测试用例也会偏向于覆盖这个组成部分的逻辑,这样就可以针对JavaScript引擎的某一个组件进行fuzz。
最终,论文决定实现一个特定于JavaScript引擎的coverage-guided fuzzer。
Requirements
这coverage-guided fuzzer的设计还需要满足下面的要求:
- fuzzer每次产生的样本必须是符合语法规则的,虽然拥有edge coverage作为引导,按理说无论变异的规则是什么样的样本一定是趋向于语法合法的,但是考虑到JavaScript引擎的体量相当庞大,为了加快fuzz的速度,变异后的样本一定要是语法合法的。
- 因为在fuzz Javascript引擎的过程中,主要测试的是JIT这样的核心模块,而这样的模块的主要工作又是分析和处理样本程序的控制和数据流,所以为fuzzer所设计的变异策略一定要是针对样本程序控制流以及数据流的。
- 在上面我们提到过一种变异方法:在AST上进行变异。这种方法很有可能生成语义不正确的测试样本,我们提到了要处理语义不正确,可以使用附加try_catch的方法,但是这样的方法,可能会影响JIT的优化导致错过一些本应该被发现的bug,所以生成语义正确的样本很重要。但是有些bug又是在语义不正确的样本下才能被发现。所以最后一个要求是,生成大概率语义正确的测试样本。
Coverage Guided JavaScript Fuzzing
在这一部分文章给出了可以满足上面要求的一种fuzzer的设计。
Concept
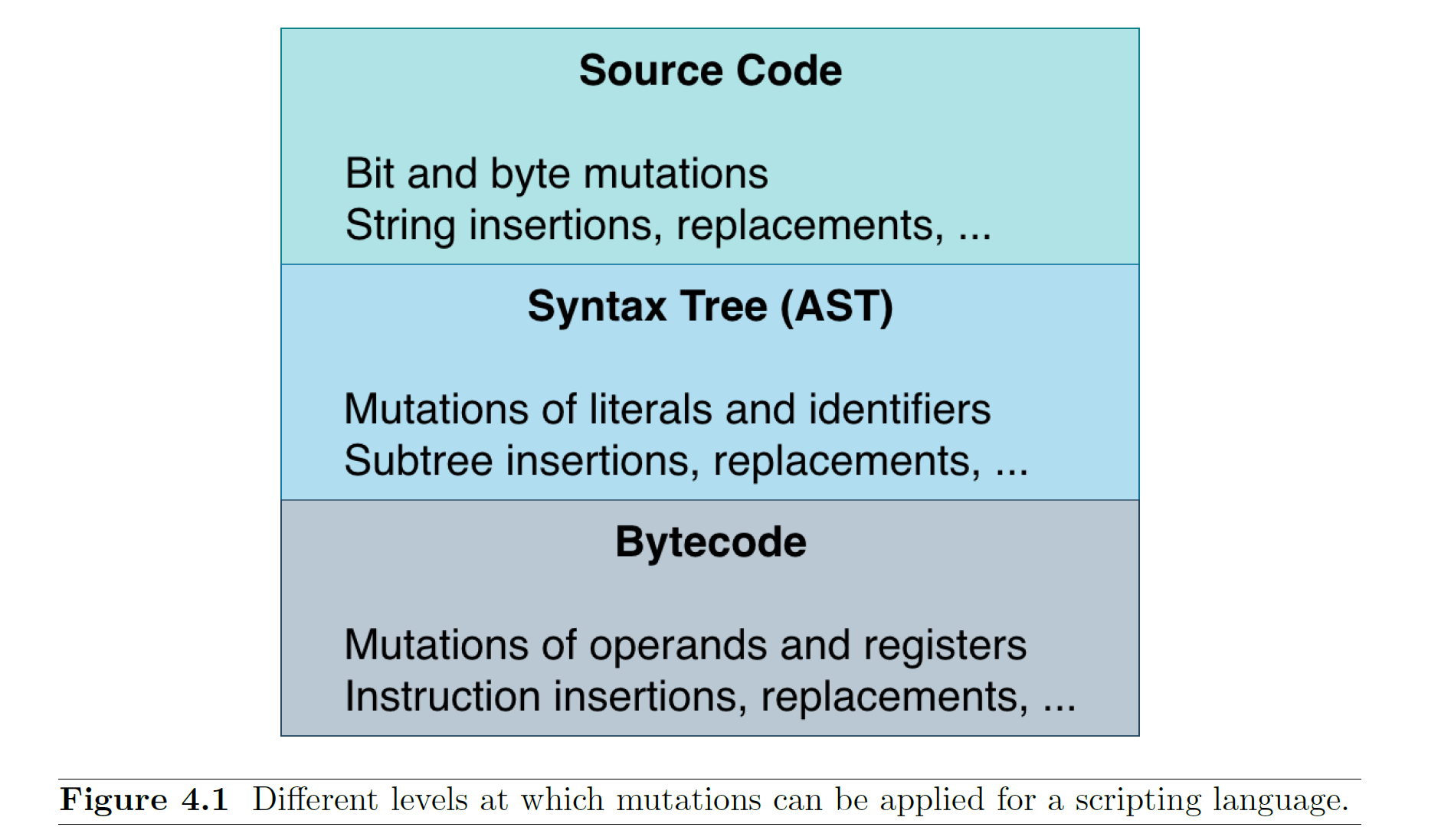
首先要考虑的就是变异的载体,要对一份JavaScript源码进行变异:
- 可以直接在源码的文本上进行变异,但是前面也已经说过了这样产生的样本可能在语法上都不是正确的。
- 或者可以在AST上进行变异,这样产生的测试样本是语法正确的,但是语义上很容易出问题。而且AST更高级更抽象,在AST上变异对控制流和数据流的影响不直观。
所以文章最终决定将字节码作为变异的载体,文章设计了一种用来表示Javascript程序的字节码叫做FuzzIL。下面的图是在三种载体上进行变异的区别:
接下来文章讨论了,在字节码上进行变异是不是可以满足上面提出的所有要求。
首先需要满足第一个要求,因为字节码变异之后还是字节码,所以只需要保证从FuzzIL永远可以转换到JavaScript,就可以保证满足第一个要求。
因为字节码更加靠近代码语义层次,更能反应控制流和数据流(比AST这样的树形结构更直观表达数据流和控制流),所以在字节码上的变异可以直接影响控制流和数据流,这样就满足了第二个需求。
对于第三个要求,因为字节码足够贴近底层,足够具体,所以每次变异对于程序逻辑的改变是很小的,这样的一次变异将一个符合语义的程序变换为一个不符合语义的程序是很难的。除此之外,FuzzIL本身也有一套用来保证语义的规则,所有的变异都必须满足这套规则,这样也保证了fuzzer所产生的测试样本的语义合法率保持在一个可以接受的水平。
(如果对比一下LangFuzz和FuzzIL的变异模式,就可以更直观的理解在字节马上变异的优点)
FuzzIL

上面是一个FuzzIL程序例子。FuzzIL中的每个指令都由:变量列表(包含输入变量和输出变量),操作符,参数(可选)。
- 变量是通过整数来标识的,并且在每个程序中都要求从零开始连续编号。
- 操作符表示了一条语句的类型,在某些情况下它代表具体的操作,但是在某些情况下它代表一类操作,具体的操作由参数来决定。
- 参数被一对单引号引用,它可能是指令中的字面值(数字,字符串,bool值……),还有可能是函数名、属性名,也有可能是指令要执行的操作(加减和比较)。
在FuzzIL中也有块指令(贴近高级语言),每个block至少由两条指令组成:一条指令代表了block的开始,还有一条代表了block的结束(参考上面的For Block)。Block也有自己的作用域,在块内部定义的变量在块外部是不能被使用的。除此之外,在Block语句(比如BeginFor)中使用的变量必须在块外被定义过。这样也符合高级语言的语义。
FuzzIL是一种SSA形式的IR,FuzzIL中所有的变量只会被赋值一次。FuzzIL为了满足多次赋值的它也拥有自己的Phi指令(和llvm中的Phi指令不太一样):
- 首先,通过Phi指令定义的变量都拥有一个初始值。
- 当需要多次赋值时,可以将这个由Phi指令定义的变量V作为Copy指令的第一个输入,这样可以由Copy指令对V进行重复的赋值。(但是在这种情况下use-def链不就不止一条了)。
rules
除此之外,FuzzIL还拥有一组规则,所有的FuzzIL程序都需要遵循这一组规则包括变异之后的程序,这样可以在一定程度上保证所有FuzzIL程序语义的合法性。规则如下:
- 变量的编号是连续的。
- 指令的所有输入值都必须是变量,没有直接值或嵌套表达式。
- 所有的变量在使用前必须先被定义,可以被定义在当前的block中或者在外围块中。
- 一个block开始指令必须后跟一个block结束指令,或者跟着另一个块开始指令比如BeginElse。
- 一个block开始指令的输入必须全部在外部块block定义。
- Copy指令的第一个输入必须是某一个Phi指令的输出。
supported operation
在作者完成这篇论文时已经支持的指令如下:
- 加载字面值:LoadInt, LoadFloat, LoadString, LoadBoolean,LoadNull,LoadUndefined。
- 创建object:CreateObject,CreateArray
- 定义函数:BeginFunctionDefinition,EndFunctionDefinition
- 访问object属性:LoadProperty,StoreProperty,DeleteProperty
- 函数和方法调用:CallFunction,CallMethod,Construct operations
一些二元运算和一元运算:BinaryOperation,UnaryOperation,CompareOperation
- 各种控制块指令:BeginWhile, BeginDoWhile, BeginFor, BeginForIn, BeginForOf,BeginIf,BeginElse,EndIf
- try-catch块:BeginTry,BeginCatch,EndTryCatch
- 以及其他控制流指令:Continue,Break,Return
Mutation
Input Mutator
从程序中选择一条或者多条IR,然后将其输入变量替换为其他随机一个变量。

在这期间需要保证替换不会打破规则,比如说先定义后使用。
Operation Mutator
替换某些拥有参数的指令中的参数,比如替换:LoadString,LoadInteger中所使用的常量,还有一些一元和二元运算符。
Insertion Mutator
调用指令生成器随机向程序插入新生成的指令,这个变异是唯一可向程序添加新生成指令的变异。
Combine Mutator
将一个完整的程序C插入到另一个程序C‘的随机位置,在插入的过程中需要调整C中的变量名和C’插入位置以下部分的变量名,以免遇到变量名冲突。

Splice Mutator
和Combine Mutator很相似但是不是插入整个程序,而是插入程序的一个切片(slice)。对slice的定义是,在slice中使用的所有变量都在slice中定义过,同样在插入的过程中需要对变量重命名以免遇到变量名冲突。文章还给出了slice的构造方法:
- 从源程序中随机选择一条指令i加入到集合中。
- 选择出所有i’加入到集合中,i’的output必须是i的某个操作数。
- 然后将i’当做i回到第二步,直到集合中所有指令使用的变量都在集合中被定义过。
- 然后将集合中所有的指令按照他们之前在源程序中的顺序拷贝到目标程序中。
Scoring
前面我们提到过guided fuzz在进行fuzz的过程中需要依据一个指标来为每个测试样本的执行情况打分(或者说是得到反馈),根据这个分数来确定是否要对这个测试样本继续进行变异。文章中所选择的指标是edge coverage,打分的方法和AFL很类似:如果一个测试样本可以在执行过程中达到新的edge那么这个样本就是我们所感兴趣的,就是高分的,将被加入到样本队列中继续变异。
但是有一点和AFL的打分策略不同的就是FuzzIL不考虑edge被执行的次数。在AFL中,如果样本在执行过程中经过一条edge的次数不同的话这个样本也将被保留。但是FuzzIL并不考虑这种情况,作者给出的解释是:因为样本中可能有循环语句的存在,循环体部分是可以被执行任意多次的,如果考虑edge执行次数的话,可能大量的变异都会是针对循环次数的变异,而这些变异可能是被浪费的。
Refinement
和AFL一样,FuzzIL也有校对的过程,文章将这个过程称为是Refinement。在将新的测试样本加入测试队列和将crash的测试样本保存在硬盘上之前都会对测试样本进行Refinement。这个过程分为三个部分:确定性检查,最小化,标准化。
Determinism
对于一个测试样本来说,如果在两次测试结果中edge coverage都是相同的那么,这个测试样本就是确定性的。
对于crash样本来说进行确定性检查是为了防止假阳性(由于OOM或其他愿意导致的程序崩溃),不具有确定性的crash也将被保存但会被标记。
对于感兴趣的测试样本来说进行确定性检查是为了后面的Refinement能够顺利进行,所以不具有确定性的测试样本即使是感兴趣的也将被丢弃。
Minimization
因为FuzzIL所有的变异都只能增大样本的体积,所以为了避免样本的体积过于庞大,需要最小化过程来削减样本的体积。这样一方面,有几个好处:
- 可以使测试的效率更快,因为过大的样本将会消耗更多的执行时间。
- 对crash样本进行削减,可以帮助分析人员更好的分析样本找到crash的原因。
- 对小体积的样本进行变异更容易获得一些有趣的特性。
对样本进行最小化的方法和AFL一样,作者设计了一些削减策略,将这些削减策略依次应用在测试样本上,如果削减前后code coverage没有发生变化,那么削减就是成功的。
最小化是一个成本很大的过程,经过作者的统计,在测试初期最小化的执行次数是要超过生成一个新的测试用例的执行次数的,但是越往后随着生成一个新的测试用例越来越难,最小化的执行次数基本上只占总执行次数的百分之一。
和AFL不同FuzzIL不能通过直接删除样本中的一部分字节来对样本进行削减,而是要从IR的层面进行削减,削减的一部分指令,这样才能保证语义和语法的正确性。下面是文章中所定义的一些削减策略:
Generic Instruction
反向遍历整个程序中的每一条非block指令,依次删除那些output没有被其他指令使用的指令,然后测试测试结果是否发生变化。
Input Reducer
对于一些拥有可变数量input的指令,比如:函数调用指令和数组创建指令,这些指令可能会拥有很多个Input,从而导致很多的指令因为被使用而无法被删除。为了解决这个问题而设计出的第二个算法是:依次删除每个可变指令中的Input然后观察,前后执行结果是否发生变化。
这些指令包括:CreateObject, CreateArray, CallFunction, CallMethod, Construct 。
而对于一些拥有不变数量参数的指令比如BinaryOperation,在文章发表时还没有很好的方法去处理这些指令的Input。
Block Reducer
上面已经考虑过了对于非block指令的削减,现在应该来考虑削减block指令。因为不同种类block指令结构和语义的不同,对于不同的block指令要单独处理。主要分成几个部分:loop block(包括for和while),if-else block,try-catch block。
loop block:直接删除block语句留下循环体,这样循环体只会被执行一次,然后测试前后的执行结果会不会发生变化。block中所有的continue和break也将被删除。
if-else block:分成三种情况if指令恒成立,恒不成立,空block。
- 判断if指令是否恒成立:只保留if block中的指令,其他的指令包括全部block指令都被删除。
- 判断if指令是否恒不成立:只保留else block中的指令,删除其他全部指令。
- 某一个block中的指令已经被删除为空:删除全部的block指令。(感觉这一条多少有点多余)
在删除之后都要测试执行前后的结果是不是发生改变。
try-catch block:也分成几种情况,try块中的指令不会引发异常,然后针对会引发一场的还有两种情况,在try块中引发异常但是try块中所有指令都不是感兴趣的;在try块中央引起异常且try块被执行的部分是感兴趣的。对这三种情况分别设计了处理方法:
- try块不会引发异常,那么catch块是不必要的,直接删除三条block指令。
- 对于第二种情况来说,这个时候直接删除block指令和整个try块,这样就会直接执行catch块。
- 对于第三种情况,paper也不能完美的处理给出的是一种妥协的办法,删除block语句和try块中的最后一条指令。这种方法没有办法最大限度的删除try块中的无用指令。
- 想了一下,这里可以先移除try块中的全部指令,如果执行结果发生变化,可以保留try块中的第一条指令,如果还是变化,就保留前两条指令,这样迭代try块中的所有指令,直到执行结果不发生变化。不知道这样的方法能不能行得通。:-)
这样对于Block指令的削减策略就设计完成了。
Special-Purpose Minimizers
但是在代码中会出现很多特殊的无效代码是没有办法由上面的这些策略削减掉,paper为这些特殊的代码模式设计了特定的处理逻辑。
关注下面的程序的第5行,这个logical or可能是没有必要的(因为v0是42),但是如果直接将这个logical or删除掉,在还原出的javascript代码中将导致logical or右操作数的函数调用变成活动代码,最终导致异常,所以logical or这个无用代码无法被被删除掉。为了处理这种情况,需要有一个专门的逻辑来处理logical or,将这个logical or和他的右操作数同时删除掉,这样就可以解决这个问题。

下面是第二种情况,函数的多层嵌套。下面的这一大串代码实际上可以被简化为perform_interesting_action(42)。paper使用内联的方法来简化这一部分代码,在整个程序中只被调用一次的函数,那一次调用将被直接展开为函数体,函数的返回值被替换为一个初值为undefine的Phi变量这个变量将在每个函数返回的地方被赋值,而return指令被删除。

Nomalization
这个部分的工作就是对FuzzIL程序中所有的变量进行重命名,让它们的编号恢复成连续的,因为在经过最小化之后有很多的指令都被删除,编号之间也出现了许多的空缺。
Fuzz-testing with FuzzIL
这部分介绍的是整个FuzzIL的工作逻辑。
首先是语料库,Mutation-based fuzz在开始fuzz之前需要有一个提供样本的语料库,变异也是在这个语料库的上开始。按照paper中的设计,FuzzIL的初始语料库只有一个FuzzIL样本程序,如下:

这个是很出乎我意料的,之前我以为,语料库中的测试样本应该都是JavaScript程序(比如一些回归测试中提供的程序),然后把这些JavaScript程序编译成FuzzIL,再变异进行测试,然后如果有感兴趣测试样本或者crash需要保存再将FuzzIL翻译成JavaScript,然后保存下来。但是实际上语料库直接提供的就是FuzzIL程序,这样的好处就是省去了编译的那一步时间,不好的地方就是没有办法使用其他现成的语料库,只能用FuzzIL手写再添加到语料库中。作者在文中也提到了,为FuzzIL实现一个从JavaScript到FuzzIL的lifter也是未来的努力方向之一。
下面是fuzzing算法的伪码:

如果每个测试样本只被变异一次很难从中发现新的感兴趣的特性,所以FuzzIL将每个样本P重复变异N次。经过亿次迭代测试并观察覆盖率之后,N的值被设置为5-15。如果N的值过小,会导致无法发现并错过一些有趣的特性;如果N的值过大,可能会对一些已经无法产生新特性的样本进行很多次的变异浪费时间。
在对一个测试样本变异并且执行之后,这个样本可能有三个结果:
- 样本造成了引擎crash,那么将这个样本Refinement之后保存在硬盘上。
- 如果样本造成引擎的不正常终止,不管是因为发生了异常还是因为运行超时,这个样本都将被丢弃。
- 在执行样本的过程中覆盖到了新的control flow eage,那么这个样本是我们所感兴趣的,将这个样本经过Refinement之后插入到变异队列中。
- 如果这个样本使引擎正常退出且没有覆盖到新的edge,这个样本不会被丢弃,下一次变异将在这个样本的基础上进行。
如果一个样本已将被变异了一个固定的次数(文章中设置的是128)那么这个样本将从变异队列中被删除。为了防止语料库被耗尽FuzzIL也被设置了最小的语料库大小为1024,如果小于这个大小就不能从语料库中删除测试样本。
Implementation
Operation and Instruction
在FuzzIL中这两部分被分开实现,Operation被实现为swift的一个类,其中携带了操作符的属性:标志位、输入输出变量的个数……下面是是Operation的定义。

具体的Operation将继承个父类,并添加上自己特有的属性比如Operation的参数。

Instruction则被实现为一个Operation的指针和一个保存输入输出变量的数组。
Program Contribution and Mutation
为了方便构建程序和对FuzzIL程序进行各种编译,fuzzer中还实现了一个ProgramBuilder(和llvm中的IRBuilder很像),ProgramBuilder提供了一系列API用于构建程序比如向程序中添加指令。
下面的例子是使用ProgramBuilder将两个程序合并:

Type System
为了保证在变异时产生的指令的语义,fuzzer中还加入了一个轻量级的类型系统和类型追踪机制用于在构建程序时为每个变量添加类型信息。类型系统可以帮助减少”Invilid Type”这样的错误,比如:生成一条随机的函数调用指令,那么调用的变量可以只从类型为Function的变量中随机选择,这样就不会出现对一个number进行函数调用的情况。
Type System的规则也非常的简单,作者一共设计了下面几种类型:Unknown, Integer, Float, String, Boolean, Object, Function。这些类型分别对应下面这些指令的输出:LoadInt, LoadFloat, LoadString, LoadBoolean, Compare, CreateObject, CreateArray。这样就拥有了类型信息产生的源头,而对于其他传递类型信息的指令比如BinaryOPeration,可以再为它们单独设计传递规则,有了这些规则之后就可以在字节码上进行有关Type System的程序分析。
Code Generator
用于生成对应的随机指令。下面是示例:

Coverage
FuzzIL没有选择自己实现插桩,而是选择使用clang自带的sanitizer-coverage,对引擎进行插桩。它将在目标程序CFG中的每个边插入__sanitizer_cov_trace_pc_guard()这样一个自定义函数,这个函数可以进行覆盖率的收集并通过共享内存将覆盖率信息反馈给fuzzer,下面是这个函数的实现:

这个桩代码和AFL的桩代码几乎一样,不一样的地方就是FuzzIL的桩代码不会统计在执行过程中一个edge被执行的次数。而共享内存初始化,index初始化等等的功能工作都在__sanitizer_cov_trace_pc_guard_init()这个函数中完成。
Program Analysis
因为测试样本的生成过程包括字节码的变异、以及从字节码向JavaScript的转换,为了给这些工作提供支持,FuzzIL还实现了一些程序分析。
- define-use analysis:确定每个变量在程序中定义的位置(reaching definition),用于实现一个能够内联表达式的降低算法。
- type analysis:确定程序中每个变量的类型信息。
- scope analysis:用一个模拟堆栈来确定在一个scope中可以访问的变量。可以在生成随机指令这个变异中使用。
- dead-code analysis:确定在程序中没有办法到达的代码(也就是不会被执行的).
Program Execution
作者比较了下面三种常用的fuzzing过程中程序的运行方法:
- Unoptimized:没有其他优化,每次fork出一个新进程然后调用execve加载目标程序。
- ForkServer:在目标程序的开头插入一段forkserver代码,这段代码将导致目标程序在进行execve初始化之后且处理输入之前被阻塞住,这样每次由forkserver接受fuzzer通知之后fork出一个新进程继续运行而不需要调用execve,节省大量时间。
- REPRL:全拼是read-eval-print-repeat-loop,在每次目标程序执行完成后程序不会终止,而是重新回到逻辑开始对程序状态进行重置,然后继续处理下一个输入。这样甚至不用fork,但是对程序本身要求也很高,要求程序自身是无状态的或者是有重置逻辑的。(AFL的persistent mode)。
比较的结果如下:

所以FuzzIL最终选择的是REPRL作为启动方式。
Infinite Loop
在对语言引擎进行fuzzing的过程中,还有需要关注的是如何处理测试样本中可能出现的无限循环。当然可以用前面提到过的timeout机制来处理无限循环,但是这样的处理可能会错过一些循环外的crash。所以FuzzIL使用插入loop guards:loop guards作为一条字节码被插入到每个函数体和循环体的开头,这条字节码的作用是在循环执行一定次数之后中断循环。下面是将这条字节码翻译为JavaScript代码之后的情况:

文章指出,虽然在不触发loop guards的情况下它对程序控制流和数据流的影响很小,但是毫无疑问的是这段代码将对JIT compiler的行为产生影响,所以在默认的情况下这个机制是被关闭的。
Crash Deduplication
FuzzIL也实现了一套crash sample去重机制,且实现逻辑和AFL相同。首先有一个crash专用的bitmap称为M,保存了之前所有crash的edge coverage信息,当发生一个新的crash时,这个crash必须覆盖了M中所没有的edge才会被保存(执行了新的路径),否则将会被认为是重复的crash。
整个论文的实现部分到这里就结束了,让我意外的是这里竟然没有介绍lifter的实现,我一直很好奇如何将FuzzIL提升为JavaScript代码的。这里只能再自己去读源码了。
Evaluation
在这个部分作者对FuzzIL进行测试。在测试部分文章介绍了几种可以加快执行速度和帮助发现漏洞的方法。
- 首先,因为JavaScript引擎中的漏洞大部分都和JIT有关,所以很多漏洞只有在触发JIT的情况下才可能被发现。而在默认的情况下一个目标函数只有被调用成千上万次才有可能触发JIT对这个函数进行编译,这将导致一个测试样本消耗很长的执行时间。为了解决这个问题,需要通过修改JavaScript引擎的源码或者在执行时为引擎添加对应的运行时参数,加快JIT的触发速度,根据文章的说法调整到10-100次调用后触发JIT是合理的。
- 第二个要做的是打开JavaScript的内部断言(assertions),这些内部断言是对程序运行时状态是否正确的一种检查,通过内部断言可以发现很多无法观测到的错误行为和非内存损坏型错误。
- 然后就是在进行fuzzing的过程中打开AddressSanitizer,它可能对内存损坏错误的发现有帮助。
- 最后,有一些比如UAF这样的漏洞通常和引擎的GC部分有关,所以为了发现这些漏洞必须经常调用垃圾收集器。这个可以通过配置引擎,来暴露一个GC调用函数来实现,或者可以通过配置引擎使引擎在每次执行结束时都进行一次GC来实现。
除了上面的改进方法之外,作者还以Js的两个具体的漏洞为背景介绍了两种比较有针对性的方法:
- 对于一些由helper function调用回调函数所产生的副作用而导致的漏洞,作者的建议是在编译引擎时时使用aggressive-inlining(-O3)可以避免错过这一类的漏洞。
- 而对于fuzz一些由复杂逻辑才能触发的漏洞,文章的建议是在发现一枚这样的漏洞时总结出这个复杂漏洞的漏洞模式,然后对引擎进行patch,让引擎在运行过程中自己检测是否出现这样的漏洞模式,如果出现就强制crash,这样可以提高发现这样漏洞的概率。(和静态分析很像,都需要总结漏洞模式)
而对于这上面两种方法的具体说明还是要到论文里面详细看一下,包括作为背景的两个漏洞的漏洞细节。
Future Work
对于FuzzIL的改进,作者提出了三个方面:
- 为FuzzIL添加可以将JavaScript转换为IR的工具,这样可以将现有的回归测试中的样本添加到语料库中。
- 扩展IR,使其可以覆盖更多的JavaScript的语法特性。
- 添加新的变异策略。