
afl-gcc
afl-gcc负责寻找afl-as所在的路径,然后将这个路径编辑在-B参数中并设置一系列其它启动参数,使用这些设置好的参数启动对应的编译器(gcc,clang)对源文件进行编译。
所以afl-gcc实际上是真正编译器的一层wrapper,afl-gcc的主要任务是传递afl-as的路径给编译器,使编译器在编译时选择afl-as作为汇编器进行插桩。下面是它的工作逻辑:
main
在main函数可以很清楚看到整个afl-gcc的骨干逻辑:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
int main(int argc, char** argv) {
[ ... ]
find_as(argv[0]);
edit_params(argc, argv);
execvp(cc_params[0], (char**)cc_params);
FATAL("Oops, failed to execute '%s' - check your PATH", cc_params[0]);
return 0;
}
先寻找路径,然后编辑参数,最后调用对应的编译器。
下面进到两个比较重要的函数中看看逻辑。
find_as
根据环境变量和afl-gcc的路径寻找afl-as的路径。
首先如果设置了
AFL_PATH这个环境变量,那么就直接将这个环境变量中的path作为afl-as的path使用,在使用之前检查一下在这个路径之下的afl-as是否可以被访问。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
[ ... ] u8 *afl_path = getenv("AFL_PATH"); u8 *slash, *tmp; if (afl_path) { tmp = alloc_printf("%s/as", afl_path); if (!access(tmp, X_OK)) { as_path = afl_path; ck_free(tmp); return; } ck_free(tmp); } [ ... ]
如果没有这个环境变量,或者环境变量为空,那么就选择afl-gcc的路径作为afl-as的路径。从argv[0]中取出afl-gcc的路径,同样检测在这个路径下afl-as是否可以被访问。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
[ ... ] slash = strrchr(argv0, '/'); if (slash) { u8 *dir; *slash = 0; dir = ck_strdup(argv0); *slash = '/'; tmp = alloc_printf("%s/afl-as", dir); if (!access(tmp, X_OK)) { as_path = dir; ck_free(tmp); return; } ck_free(tmp); ck_free(dir); } [ ... ]
如果这两个方法都不成功,那么就测试AFL_PATH这个预处理器宏是不是符合条件。如果这三种都不符合条件就抛出异常。
1 2 3 4
if (!access(AFL_PATH "/as", X_OK)) { as_path = AFL_PATH; return; }
edit_params
为真正的编译器设置启动参数,最主要的是通过-B参数将afl-as的路径传递给编译器,使编译器以afl-as作为汇编器。
为参数分配内存之后,首先要做的是选择正确的编译器,选择的依据是使用的wrapper的名字,afl-gcc对应gcc、afl-clang对应的是clang……实际上afl-gcc,afl-clang……都是一个东西,都只不过是afl-gcc的符号链接。
- 选择好编译器之后,进入处理参数的循环,在这个循环中将对afl-gcc的参数进行处理,将它们转化为对应编译器的参数:
- 跳过-B,-pipe,-integrated-as
- 设置各种标志位,如果afl-gcc拥有一些sanitizer和内存安全有关的参数,那么将对应的标志位置位。
- 对于其他的不特殊的参数直接copy到编译器的参数中。
在afl-gcc的参数都处理完毕之后,根据处理中置位的各种标志位,afl-gcc的环境变量为gcc生成参数。其中最重要的莫过于设置
-B参数并将afl-as的路径作为-B参数的prefix,这样当gcc需要汇编器的时候就会拿到afl-as作为汇编器。实际上直接在执行g++时加入参数
-B[as_path],也可以调用afl-as为程序插桩:![image-20220728141642142]()

afl-as
afl-as的输入是源码经过GCC翻译后生成的汇编代码,而afl-as的作用就是识别汇编代码中所有的基本快,在每个基本块前插桩,这样在执行每个基本块时都会执行桩代码将这一次执行记录起来,而记录的所有数据就是整个一次执行过程中的代码覆盖率。
main
在main函数中可以看出整个afl-as的主干逻辑:
- 在main中为BB生成随机数提前设置种子。
- 对一些设置的环境变量做出响应:AFL_INST_RATIO(基本块插桩的比例),AFL_USE_ASAN(在开启asan之后将会生成一些额外的基本块,AFL选择用概率弥补这些额外基本块造成的影响)。
- 在afl-as完成插桩之后,将会启动一个真正的as程序完成汇编过程,所以调用
edit_params()函数为as设置参数。 - 然后调用
add_instrumentation()完成插桩。 - 最后fork出一个子进程并启动as对完成插桩的汇编文件进行汇编。
edit_prams
在这个函数中为真正的as设置参数,除了设置参数之外这个函数还将确定插桩之后输出的汇编文件名,通过输入的汇编文件的路径判断汇编文件的来源……
插桩之后的输出将被保存到一个新创建的临时文件中,为了创建这个临时文件
edit_prams()先获取临时文件目录。1 2 3 4 5
[ ... ] if (!tmp_dir) tmp_dir = getenv("TEMP"); if (!tmp_dir) tmp_dir = getenv("TMP"); if (!tmp_dir) tmp_dir = "/tmp"; [ ... ]
然后为as的参数申请内存。
为as设置第一个参数:as的路径。这个参数有两个来源:要么从AFL_AS这个环境变量中取,要么就是”as”这个字符串。
之后一个for循环将afl-as除了最后一个参数之外的参数都取出来copy给as的参数。中间还判断32位和64位模式。
然后取出afl-as的最后一个参数argn也就是afl-as输入汇编文件的路径。对于这个参数也有很多种情况:
如果argn以’-‘开始,那么它不是一个文件:
1 2 3 4 5 6 7
if (input_file[0] == '-') { if (!strcmp(input_file + 1, "-version")) { just_version = 1; modified_file = input_file; goto wrap_things_up; }
- 可能是”-version”说明这次启动不是要插桩而是查看afl-as的版本直接去打印版本了。
- 或者它是其他的东西”-xxxxx”那么说明这次启动不是由gcc发起的一次启动,是无法处理的情况所以退出。
比较文件的路径,如果这个文件在临时文件夹中,那么这次启动是由gcc的一次标准调用,且输入为汇编文件。
如果不在临时文件夹中,那么这一次的启动可能不是标准的调用,传入的文件可能不是汇编文件格式,也没有办法对这种格式的文件进行插桩,所以只需要设置标志位
pass_thru停止插桩,直接原封不动copy文件就可以。1 2 3
if (strncmp(input_file, tmp_dir, strlen(tmp_dir)) && strncmp(input_file, "/var/tmp/", 9) && strncmp(input_file, "/tmp/", 5)) pass_thru = 1;
最后为生成输出文件名,这个输出的临时文件将作为as的输入,所以要放在参数的最后。
1 2 3 4 5 6 7 8
modified_file = alloc_printf("%s/.afl-%u-%u.s", tmp_dir, getpid(), (u32)time(NULL)); wrap_things_up: as_params[as_par_cnt++] = modified_file; as_params[as_par_cnt] = NULL;
add_instrumentation
真正的插桩过程都在这个函数中。这个函数的主要逻辑就是对汇编代码的每一行进行匹配,判断汇编码是否符合条件。将除代码段以外的部分原封不动的拷贝到输出文件中,对代码段中的每个基本块开始进行插桩。然后是逻辑的细节:
每次读取汇编代码中的一行,先不对这一行做匹配和分析,如果在读入这一行时下面的标志位都符合条件,且这一行的汇编指令看起来也是代码的话,那么就在这一行之前插桩。
1 2 3 4 5 6 7 8 9 10
if (!pass_thru && !skip_intel && !skip_app && !skip_csect && instr_ok && instrument_next && line[0] == '\t' && isalpha(line[1])) { fprintf(outf, use_64bit ? trampoline_fmt_64 : trampoline_fmt_32, R(MAP_SIZE)); instrument_next = 0; ins_lines++; }
所以在继续下去之前需要先了解一下这些标志位都代表了什么:
- pass_thru:在上一个函数中设置的,这个标志位代表不需要插桩,将input_file中的内容原封不动的拷贝到output_file中。
- 一系列skip标志位:标志了这个基本块可能是一些不能处理的特殊的基本块,跳过这些基本块的插桩。
- instr_ok:表示现在的位置是在代码段。
- instrument_next:这是一个基本块的开始,这个位置需要插桩。
插桩完成后,将输入的这一行也copy到输出文件中,因为不管怎么样都需要原本的内容都不能被修改。
在完成copy和插桩的工作之后才是对这一行的代码进行分析,确定标志位,下一步要做的事情。这一部分很长,但是逻辑并不难看懂:作者总结出了gcc生成汇编代码的一系列规则特征,它用每一行的汇编代码去匹配这些特征确定这一行的含义,并设置标志位。
在最后如果插桩次数不为0也就是
ins_lines这个变量不为0,向汇编代码的最后插入main_payload_(至于这部分汇编代码的作用后面再说)。
到这里插桩的过程就结束了,但是其中仍然有几个需要注意的地方:
首先在插桩时,并不只是匹配代码特征,这里将会用上一开始的随机数种子。插桩时同样会考虑插桩的密度(在开启asan的时候因为有额外的分支,所以要概率补偿)。概率默认值是100%(如果用asan编译是1/3),它为每个插桩点生成一个随机数,如果这个随机数
余100小于概率(maybe 100),那么就允许插桩,否则不允许。这样就控制了插桩的密度。1 2 3 4 5 6 7 8 9 10
if (line[1] == 'j' && line[2] != 'm' && R(100) < inst_ratio) { fprintf(outf, use_64bit ? trampoline_fmt_64 : trampoline_fmt_32, R(MAP_SIZE)); ins_lines++; } # define R(x) (random() % (x))
谈了这么长时间插桩的逻辑,还没有看过桩究竟是什么样子。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
static const u8* trampoline_fmt_64 = "\n" "/* --- AFL TRAMPOLINE (64-BIT) --- */\n" "\n" ".align 4\n" "\n" "leaq -(128+24)(%%rsp), %%rsp\n" "movq %%rdx, 0(%%rsp)\n" "movq %%rcx, 8(%%rsp)\n" "movq %%rax, 16(%%rsp)\n" "movq $0x%08x, %%rcx\n" "call __afl_maybe_log\n" "movq 16(%%rsp), %%rax\n" "movq 8(%%rsp), %%rcx\n" "movq 0(%%rsp), %%rdx\n" "leaq (128+24)(%%rsp), %%rsp\n" "\n" "/* --- END --- */\n" "\n";
这段代码实际上就是调用
__afl_maybe_log这个函数,这个函数的逻辑在后面介绍qemu_mode的时候将会介绍(看汇编有点难)。所以这个函数也必须被塞进汇编代码中,才能在生成机器码时被解析,而最后插入的main_payload_就是这个函数的逻辑。
然后把经过afl-gcc编译之后的二进制文件放到IDA里看一看插桩之后是什么样子:
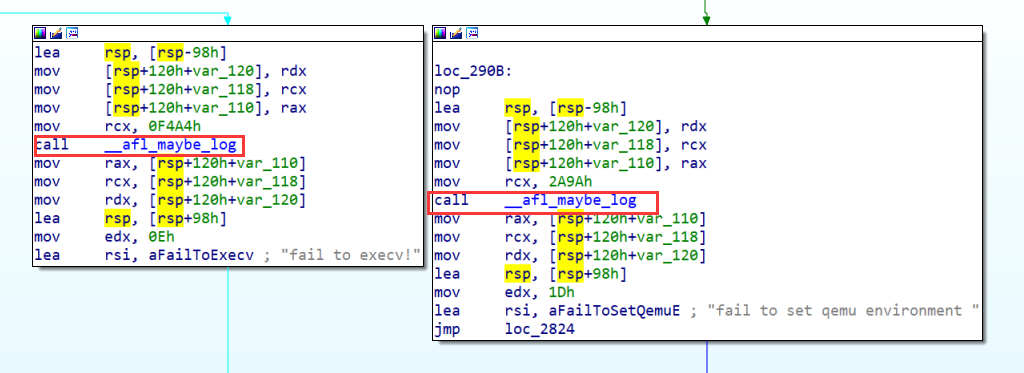
这样插桩部分的工作就看完了,然后就是afl如何进行fuzz方面的工作。
afl-fuzz
这一部分是整个AFL工作的核心逻辑。
main
设置随机数种子,之后是调用getopt()对afl-fuzz传入的参数进行处理。
在处理完传入的参数之后,调用setup_signal_handlers设置fuzzer对于信号的处理程序。
调用
check_asan_opts(),读取ASAN_OPTIONS这个环境变量,检查其中有关asan的设置。如果以-M并行启动afl。调用
fix_up_sync()函数处理sync_id。检查是不是存在dumb_mode,crash_mode,qemu_mode共存的情况,其中dumb_mode指的是盲fuzz。
读取一系列环境变量,并根据环境变量的值设置以后要使用的标志位。
调用
save_cmdline()原来的命令行参数全部保存在一个缓冲区中,不同的参数间用’ ‘隔开。调用
check_if_tty()检查当前是否运行在一个tty上,如果不是置位not_on_tty。调用
get_core_count()通过计算当前正在运行的进程数量和cpu数量之间的关系得出系统当前的压力,并打印提示信息。调用bind_to_free_cpu()使用刚计算出的cpu个数和/proc/xxx/status中每个进程使用cpu的信息,找到一个空闲的cpu,并将这个afl绑定在这个空闲的cpu上。
调用
check_crash_handling()函数检查/proc/sys/kernel/core_pattern中的内容查看系统上是否开启了core dump,因为core dump会延长程序的退出时间导致效率变低,也有可能因为core dump而超过time而导致time out的误判。一旦检查到开启了core dump afl将退出并提示用户关闭core dump。调用
check_cpu_governor()检测当前cpu频率的调整模式,如果cpu工作在onedemand模式下不利于afl的工作,afl将退出并提示更换cpu的频率调整模式。调用setup_shm()为afl创建共享内存,共享内存将在统计代码覆盖率时使用。
调用init_count_class16()初始化分类数组。
- 调用
setup_dirs_fds()创建输出目录。分成两种情况:- 如果目录已经存在:
- 目录已经被上锁,那么这个目录可能正在被另一个AFL进程使用,用户需要选择一个新的目录。
- 目录没有被上锁,那么这个目录可能是在之前的fuzz中使用过的目录,目录中可能还保存着一些工作内容,如果其中的工作内容太多AFL会退出并要求恢复之前的工作(衡量的标准是文件上次更新的时间 - 创建时间 > 25个小时)。而指定恢复工作的语法是将input dir指定为’-‘。
- 如果目录不存在那么创建这个目录,并为这个目录加锁。
- 如果目录已经存在:
调用read_testcases()从input dir中读取全部的测试用例,并将其信息(名字,长度……)保存在一个队列中。
调用load_auto()从/.state/auto_extras/文件中加载自动生成的字典token。
调用
pivot_inputs()为testcase队列中每个testcase在output file中创建硬链接,如果不能创建连接,那么将testcase copy到output file中。output file中的每个testcase将以xxxx/queue/id:[num]orign:[filename]的格式来命名。(这中间还涉及一些恢复模式的逻辑不太清楚)如果在AFL的启动参数中加入了
-x那么接下来将调用load_extras()从指定的文件文件夹中加载字典。如果没有
-t参数调用find_timeout()从状态文件中读取timeout,但是前提是必须是在恢复模式下。调用
detect_file_args()替换参数中的@@。将他替换为-f指定的输入文件,或者是默认的xxxx/.cur_input。如果没有使用
-f指定变异数据的输出文件调用setup_stdio_file()将变异的输出文件指定为out_dir/.cur_input。(只有在@@模式下才可以指定-f,如果从标准输入读取那么默认是使用.cur_inpt作为保存testcase的文件夹)。调用check_binary()检查fuzzer的目标二进制文件。
调用
get_qemu_argv()为qemu mode生成启动参数(如果在qemu mode之下的话),生成格式为:path/to/afl-qemu-trace – target_file …这样格式的参数,当fuzz时将使用这样的参数来启动qemu。在上面所有的准备工作都完成之后调用perform_dry_run()函数将队列中所有testcase测试一遍,来确定fuzzer可以正确运行。
调用cull_queue()根据
top_rated中保存的testcase修剪队列,使队列更加精简。调用
write_stats_file()更新状态文件,这个状态文件可以用于无人值守的监视。调用
save_auto()将自动生成的Token写入到文件中。这个函数只有在auto_changed标志位被置位的情况下才会执行逻辑。然后是一个
while(1)的循环来开始整个fuzz的过程。- 一开始先调用
cull_queue()精简testcase队列。 - 然后判断
queue_cur是否为NULL,如果是的话说明刚刚完成一轮对于队列中testcase的遍历;或者是刚刚开始第一轮fuzz。进行一系列的初始化操作:queue_cycle++代表开始新的一轮,这个变量代表了轮数。current_entry和cur_skipped_paths都设置为0。queue_cur设置为队列的开头。- 如果这一轮
prev_queued和queued_paths的值一样,那么意味着上一轮fuzz中没有产生新的testcase,将use_splicing设置为1,这意味着可能要重新组合一些testcase。如果use_splicing已经为1,那么cycles_wo_finds加1代表testcase连续没有变化的轮数。 - 接下来将
prev_queued设置为queued_paths。
- 调用fuzz_one开始fuzz。
- 如果不手动中断这个循环将一直运行下去,每次fuzz完一个testcase,对新生成的testcase进行校准,然后再次回到循环开头,精简队列。
- 一开始先调用
当
stop_soon这个标志位被置位的时候(可能是手动退出,也可能由afl本身的逻辑控制退出),while循环会退出,代表fuzz结束,再退出之后将进行一些收尾工作:- 如果不是由手动发出信号引起的退出那么要kill掉forkserver和被测试的程序。
- 将fuzz状态写回到文件中,因为用户可能还想从这一次中断的fuzz中恢复。
- 然后保存自动生成的token。
- 最后释放掉申请的所有内存
在完成这些全部工作之后afl就会退出。
setup_signal_handlers
有关一些设置信号和信号处理程序的内容:
https://www.cnblogs.com/52php/p/5813867.html
https://man7.org/linux/man-pages/man7/signal.7.html
在afl-fuzz中将信号分成了几个种类,相同种类的信号将被设置相同的信号处理程序:
SIGHUP,SIGINT,SIGTERM:挂起,crtl + c,终止(通常由另一个进程发出来礼貌(可以被忽视)的结束另一个进程比如kill)这些信号标志着fuzz过程的停止,所以当接收到这些信号时信号处理程序将关闭forkserver和子进程。
1 2 3 4 5 6 7 8
static void handle_stop_sig(int sig) { stop_soon = 1; if (child_pid > 0) kill(child_pid, SIGKILL); if (forksrv_pid > 0) kill(forksrv_pid, SIGKILL); }
SIGALARM:标志timeout,如果此时此刻有子进程正在运行那么kill掉子进程,如果没有子进程但是有forkserver就kill掉forkserver。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
static void handle_timeout(int sig) { if (child_pid > 0) { child_timed_out = 1; kill(child_pid, SIGKILL); } else if (child_pid == -1 && forksrv_pid > 0) { child_timed_out = 1; kill(forksrv_pid, SIGKILL); } }
- SIGWINCH:调整窗口大小,设置
clear_screen标志位为1。 - SIGUSR1:由用户发起的跳过当前这一次的输入。设置
skip_requested标志位为1. - SIGTSTP,SIGPIPE:忽略掉这两个信号
bind_to_free_cpu
要将afl绑定在空闲的cpu上首先要做的就是查看哪些cpu还没有被使用。在/proc/xxxx/status这个文件保存了一个正在运行的进程的状态,其中有一项是cpus_allowed_list代表了这个进程可以调度的cpu。afl作者使用的方法是:
创建一个数组代表机器上可能存在的cpu,数组大小为4096代表可能有这么多的cpu。
扫描所有的进程的status文件,并截取其中的cpus_allowed_list字段,将数组中对应项置1,表示不空闲。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
while (fgets(tmp, MAX_LINE, f)) { u32 hval; /* Processes without VmSize are probably kernel tasks. */ if (!strncmp(tmp, "VmSize:\t", 8)) has_vmsize = 1; if (!strncmp(tmp, "Cpus_allowed_list:\t", 19) && !strchr(tmp, '-') && !strchr(tmp, ',') && sscanf(tmp + 19, "%u", &hval) == 1 && hval < sizeof(cpu_used) && has_vmsize) { cpu_used[hval] = 1; break; } } ck_free(fn); fclose(f); }
最后根据根据之前统计的最大cpu数量,扫描数组得到空闲的cpu。
然后调用sched_setaffinity()绑定cpu。这个方法中唯一的问题就是有些进程是可以在多个cpu上调度的,而作者是跳过这些进程的,所以最终得到的结果也不一定准确。
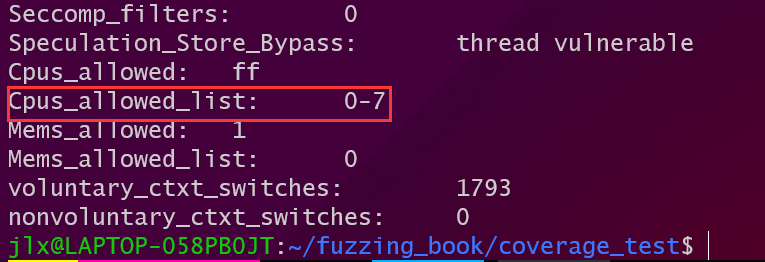
对于0-7这样存在多个可调度cpu的进程是忽略的。
setup_shm
为afl-fuzz创建共享内存,这块共享内存是afl-fuzz和被测试子进程通讯的工具:子进程BB中的桩代码将执行信息写在这篇共享内存中,当子进程执行结束后,将由afl-fuzz读取这篇内存中的所有的执行信息并计算出代码覆盖率。
1
2
3
shm_id = shmget(IPC_PRIVATE, MAP_SIZE, IPC_CREAT | IPC_EXCL | 0600);
if (shm_id < 0) PFATAL("shmget() failed");
afl并没有选择使用mmap创建共享内存,而是选择使用shmget()来创建共享内存,下面是有关shmget使用的文章:
- https://www.cnblogs.com/52php/p/5861372.html
- https://man7.org/linux/man-pages/man2/shmget.2.html
在创建完成之后,afl-fuzz将返回的fd设置为环境变量SHM_ENV_VAR的值,这样fuzz在启动子进程时,子进程可以从环境变量中取出fd,再调用shmat完成映射,就可以与afl-fuzz一起访问这片共享内存。
init_count_class16
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
static const u8 count_class_lookup8[256] = {
[0] = 0,
[1] = 1,
[2] = 2,
[3] = 4,
[4 ... 7] = 8,
[8 ... 15] = 16,
[16 ... 31] = 32,
[32 ... 127] = 64,
[128 ... 255] = 128
};
static u16 count_class_lookup16[65536];
EXP_ST void init_count_class16(void) {
u32 b1, b2;
for (b1 = 0; b1 < 256; b1++)
for (b2 = 0; b2 < 256; b2++)
count_class_lookup16[(b1 << 8) + b2] =
(count_class_lookup8[b1] << 8) |
count_class_lookup8[b2];
}
在这个函数中将使用count_class_lookup8(class8)这个数组为count_class_lookup16(class16)初始化。按照class16中元素的索引在class8中为它选择合适的值。实际上这是一次对于class16中元素的分类,将class16分成了9 * 9 = 81个部分,每个部分中的值都相同,举个例子:
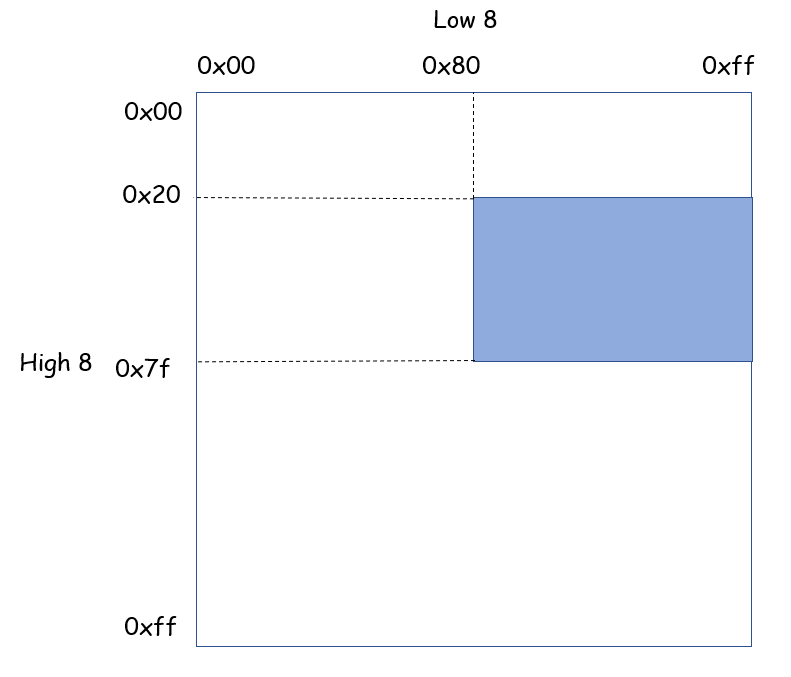
上面蓝色部分中所有元素的值都是0x4080。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
static inline void classify_counts(u64* mem) {
u32 i = MAP_SIZE >> 3;
while (i--) {
/* Optimize for sparse bitmaps. */
if (unlikely(*mem)) {
u16* mem16 = (u16*)mem;
mem16[0] = count_class_lookup16[mem16[0]];
mem16[1] = count_class_lookup16[mem16[1]];
mem16[2] = count_class_lookup16[mem16[2]];
mem16[3] = count_class_lookup16[mem16[3]];
}
mem++;
}
}
将class16分类之后,再使用class16为共享内存中的覆盖率数据分类。这样所有的内存覆盖率数据将被分为9类。
read_testcases
在AFL中参数中指定的input file保存了所有的testcase,而这个函数希望将所有满足条件的testcase放在一个队列中。
检查input dir是否可以被正常访问,然后按照目录中所有条目(包括文件和子目录)的d_name对条目的drent进行排序,并保存在一个drent数组中。如果有需要对整个数组进行打乱。
1
2
3
4
5
6
7
8
9
10
11
12
fn = alloc_printf("%s/queue", in_dir);
if (!access(fn, F_OK)) in_dir = fn; else ck_free(fn);
[ ... ]
nl_cnt = scandir(in_dir, &nl, NULL, alphasort);
[ ... ]
if (shuffle_queue && nl_cnt > 1) {
ACTF("Shuffling queue...");
shuffle_ptrs((void**)nl, nl_cnt);
}
[ ... ]
之后扫描整个drent数组,检查每一个元素是否有权访问、是否为文件、size是否过大、是否已经被fuzz过。如果这些指标全部都合格的话,就调用add_to_queue()将这个文件加入到testcase的queue中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
if (lstat(fn, &st) || access(fn, R_OK))
PFATAL("Unable to access '%s'", fn);
/* This also takes care of . and .. */
if (!S_ISREG(st.st_mode) || !st.st_size || strstr(fn, "/README.testcases")) {
ck_free(fn);
ck_free(dfn);
continue;
}
if (st.st_size > MAX_FILE)
FATAL("Test case '%s' is too big (%s, limit is %s)", fn,
DMS(st.st_size), DMS(MAX_FILE));
[ ... ]
if (!access(dfn, F_OK)) passed_det = 1;
ck_free(dfn);
add_to_queue(fn, st.st_size, passed_det);
在testcase queue中每一个testcase都被表示成一个queue_entry这样的数据结构。在queue_entry中保存了一个testcase的所有信息。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
struct queue_entry {
u8* fname; /* File name for the test case */
u32 len; /* Input length */
u8 cal_failed, /* Calibration failed? */
trim_done, /* Trimmed? */
was_fuzzed, /* Had any fuzzing done yet? */
passed_det, /* Deterministic stages passed? */
has_new_cov, /* Triggers new coverage? */
var_behavior, /* Variable behavior? */
favored, /* Currently favored? */
fs_redundant; /* Marked as redundant in the fs? */
u32 bitmap_size, /* Number of bits set in bitmap */
exec_cksum; /* Checksum of the execution trace */
u64 exec_us, /* Execution time (us) */
handicap, /* Number of queue cycles behind */
depth; /* Path depth */
u8* trace_mini; /* Trace bytes, if kept */
u32 tc_ref; /* Trace bytes ref count */
struct queue_entry *next, /* Next element, if any */
*next_100; /* 100 elements ahead */
};
在add_to_queue()中将使用头插法将每一个新的entry插入到队列中,enrty之间使用next指针进行连接,索引为100整数倍的指针还将使用next_100指针进行一次额外的连接。
load_auto
(TODO:how are the Tokens selected? )
所有自动生成的字典Token都被保存在xxxx/.state/auto_extras/这个目录下,每个Token保存在一个文件中,每个Token的最短长度为3个字节,而最长长度为32个字节。load_auto会依次将这些Token从对应的文件中读出来,然后做以下判断:
- 首先判断Token的长度是否在合理的范围内。
(下面的部分逻辑在maybe_add_auto()函数中)
然后判断Token是否在一些常用的Token集中,如果在的话就直接返回了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
if (len == 2) { i = sizeof(interesting_16) >> 1; while (i--) if (*((u16*)mem) == interesting_16[i] || *((u16*)mem) == SWAP16(interesting_16[i])) return; } if (len == 4) { i = sizeof(interesting_32) >> 2; while (i--) if (*((u32*)mem) == interesting_32[i] || *((u32*)mem) == SWAP32(interesting_32[i])) return; }
判断Token是否和从字典中加载的Token有重复(保存在extras数组中),如果有重复就返回。
判断Token是否和已经自动生成的Token有重复(保存在a_extras数组中),用重复就将数组中对应元素的hit_cnt++,如果没有的话将这个Token加入到a_extras数组中。
在这个函数结束之后目录中所有的auto selected Token都将被处理一遍。
load_extras
因为AFL是一个基于变异的fuzzer,他通过对testcase进行随机的变异以期望能够扩大在处理testcase时所走过的执行路径。但是变异的随机性又导致AFL很难应付那些使用特定格式协议数据进行交互的程序:testcase在经过AFL变异之后在大多数情况下对这些程序来说无效的,这样可能在对于数据的预处理阶段就因为数据格式错误而导致程序退出;可能只有经过大量的变异才能够生成一次有意义的数据,fuzz的效率变得相当低。
当然可以通过设计一个专门的,特定于协议的并带有语法模板的fuzz引擎,来出来这样的情况,但是这样要花费大量的时间。AFL为这样的问题提供了折中的解决方案,这个解决方案主要依赖于两个机制:coverage guided,dictionary。
字典指的是AFL不为这些协议构建语法模板,而是将其中一些有意义的Token提取出来,构成一个Token字典。在变异时使用字典中的Token进行拼凑。虽然这样仍然可能生成很多的无效语句,但是借助于coverage guided机制可以将这些无效语句淘汰掉,并且这样的效率要比纯随机变异的效率要高的多。
而load_extra这个函数的作用就是从-x所指定的字典目录或者字典文件夹中加载字典。字典的加载有两种模式。
file mode
可以将所有的Token都写在一个文件中,当然也要遵循一定的语法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
#
# AFL dictionary for GIF images
# -----------------------------
#
# Created by Michal Zalewski <lcamtuf@google.com>
#
header_87a="87a"
header_89a="89a"
header_gif="GIF"
marker_2c=","
marker_3b=";"
section_2101="!\x01\x12"
section_21f9="!\xf9\x04"
section_21fe="!\xfe"
section_21ff="!\xff\x11"
在这种模式下可以有注释,以#开头的一行代表注释。所有的Token都是name=”value”的格式,且不允许有不可见字符,所有的不可见字符都必须转译。
在这种模式下可以为Token指定level,格式为:name_@level=”value”;同时也可以为字典文件指定level(默认是0),格式:filename_@level。只有当Token 的level小于file的level才可以被加载,否则将被跳过。
在load_extras()函数中会将-x的参数当作目录打开,如果无法打开(不是目录),则会调用load_extras_file()这个函数去加载文件中的Token。
dir mode
如果-x的参数可以当作目录打开,那么就进入dir mode。
在这个模式中,每个Token对应一个文件,Token的加载比file mode简单(因为不用处理文本),直接从文件中读出的内容就是Token允许包含不可见字符。
汇总
最终所有的Token都将被保存在extras数组里,调用qsort()对所有的Token按照Token的长度进行排序。
check_binary
首先检查传入的target file(t_file)的路径,如果是绝对路径或者相对路径都没有问题,如果传入的t_file只是一个文件名那么需要从env中获得拿到对应的路径并和文件名拼接在一起(没有路径只通过一个文件名没有办法访问文件)。
然后将会对有路径的二进制文件做以下的检查:
- 检查二进制是否被保存在临时目录下,AFL不希望二进制文件被保存在临时目录下。
- 用mmap将二进制文件映射到内存空间中。
- 检查文件开头是否有”#!”这样的字符,表示这个文件是一个脚本文件,如果这是一个脚本文件AFL将会退出。
- 检查文件开头是否有代表ELF文件的魔数,AFL希望这是一个t_file是一个ELF文件,所以如果文件开头不包含这样的魔数,AFL也将会退出。
- 在白盒模式下检查ELF文件是否拥有”__AFL_SHM_ID”这样的字符串(使用
memmem()函数),如果没有那么这个文件根本没有被插桩,所以直接退出。 - 在黑盒模式下检查ELF文件是否拥有”__AFL_SHM_ID”这样的字符串,如果有的话说明这个文件在黑盒模式下被插了桩,这是不应该的所以直接退出。
- 最后,通过检查二进制文件中字符串判断t_file是否支持:Persistent mode,Deferred forkserver。
这个函数的工作就是检查二进制文件的合理性和正确性。
perform_dry_run
从这个函数中基本上也可以看出AFL在真正使用测试用例测试程序的逻辑。
在将测试用例读入内存之后,调用calibrate_case()来对每一个测试用例进行校对,检查测试用例在使用过程中是否会发生问题。
根据calibrate_case()的返回的错误代码,来向用户输出错误信息和错误的解决办法。
最后在将队列中所有的测试用例遍历完一遍之后,根据所统计的出现超时错误的testcase的个数向用户打印提示信息,在错误比较多的情况下将提醒用户检查设置或者更换测试用例。
在fuzz一开始必须保证所有的测试用例都能使target_file正常运行,不能出现崩溃的情况。
calibrate_case
这个函数的作用是:
- 一方面在fuzzer正式工作之前,通过运行来校对testcase是否能正常使用。
- 另一方面在多次运行同一个testcase的过程中如果发现code coverage在不断变化,将这个testcase标记为可变的testcase。所以另一个作用就是在每次发现新的路径时,对testcase进行测试检测它是否为可变的testcase。
首先,设置stage_name标识当前的阶段,并且设置stage_max来确定在这个阶段对于一个测试用例的测试次数。
在不是dumb mode和no forkserver的情况下,如果forkserver_pid为空那么调用init_forkserver初始化forkserver。
在初始化forkserver之后就要正式开始这个函数的功能逻辑。
首先检查传入的testcase的bitmap校验和是否为0,这个校验和是对bitmap的一个hash,可以用来判断前后两次执行过程走过的路径是否有不同(在每次执行前都会将上一次的执行置位的bitmap清零)。
1 2 3 4 5 6 7 8
if (q->exec_cksum) { memcpy(first_trace, trace_bits, MAP_SIZE); //check wether the bitsmap is changed in the previous excution hnb = has_new_bits(virgin_bits); if (hnb > new_bits) new_bits = hnb; }
- 如校验和不为0那么说明这个testcase并不是第一次被使用,所以就不是第一个作用了。将bitmap copy到
first_trace中作为测试前bitmap的参考。并调用has_new_bits()检查在上一次执行之后是bitmap中是否有变化,afl需要这个函数返回值来指示是这个testcase是否会导致新的块被执行。 - 如果为0那么说明这个testcase是第一次被执行,还没有bitmap作为参考,所以不需要做处理。
- 如校验和不为0那么说明这个testcase并不是第一次被使用,所以就不是第一个作用了。将bitmap copy到
之后将是一个大循环,多次使用相同的testcase进行测试,在测试后比较前后校验和,并且调用
has_new_bits()检查bitmap的更新情况。这个大循环是对testcase是否导致可变的执行路径的一个检验,如果校验和不停的变化,那么这个testcase就是一个可变的。在这个过程中还将使用first_trace与测试后的bitmap进行比较统计发生变化的块的数量并打印在屏幕上。除了统计可变信息之外,在这个过程中还将收集执行testcase过程中的错误信息,调用的函数为run_target,如果在testcase执行过程中发生错误,这个函数将返回错误信息(用于第一个功能)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54
for (stage_cur = 0; stage_cur < stage_max; stage_cur++) { u32 cksum; if (!first_run && !(stage_cur % stats_update_freq)) show_stats(); write_to_testcase(use_mem, q->len); fault = run_target(argv, use_tmout); /* stop_soon is set by the handler for Ctrl+C. When it's pressed, we want to bail out quickly. */ if (stop_soon || fault != crash_mode) goto abort_calibration; if (!dumb_mode && !stage_cur && !count_bytes(trace_bits)) { fault = FAULT_NOINST;//根本就没有插桩!!! goto abort_calibration; } cksum = hash32(trace_bits, MAP_SIZE, HASH_CONST); if (q->exec_cksum != cksum) { hnb = has_new_bits(virgin_bits); if (hnb > new_bits) new_bits = hnb; if (q->exec_cksum) { u32 i; for (i = 0; i < MAP_SIZE; i++) { if (!var_bytes[i] && first_trace[i] != trace_bits[i]) { var_bytes[i] = 1; stage_max = CAL_CYCLES_LONG;//检测到有新的块被执行增加执行次数 } } var_detected = 1; } else { q->exec_cksum = cksum; memcpy(first_trace, trace_bits, MAP_SIZE); } } }
在循环结束之后根据执行情况更新bitmap中保存的信息,然后调用update_bitmap_score()判断当前的testcase是不是更加优秀。最后将stage_name,stage_cur,stage_max都更新到原来的值之后退出,标志着这一次的测试完成。
init_forkserver
对于forkserver的工作原理这里暂时不过多涉及,在后面会有具体的一部分记录forkserver和fuzzer的通信过程。
AFL在fuzz过程中会为target_file创建大量的进程,并使用testcase对这些新进程进行测试,但是这些进程的创建并不由fuzzer本身进行,而是由forkserver进行,而fuzzer本身只负责创建一个forkserver。fuzzer通过一套协议与forkserver之间进行通信,控制整个过程。所以在fuzz之前需要先初始化一个forkserver为后面的工作做准备。
fuzzer和forkserver之间使用两条管道进行通信:st_pipe和ctl_pipe。fuzzer通过st_pipe获得forkserver的状态,并通过ctl_pipe向forkserver发送控制信息。
在init_forkserver()首先创建这两条管道,然后fork出一个新进程作为forkserver(fs),然后对fs做出下面的设置:
为fs设置fd limit和mem limit。
将fs的标准输出和标准错误重定向到/dev/null。
如果afl的启动参数指定了
-f(变异后的testcase所保存的文件),将fs的标准输入重定向到/dev/null(因为要从文件中读而不是标准输入),如果没有指定-f将标准输出直接重定向到setup_stdio_file()所打开的默认输出文件的文件描述符。1 2 3 4 5 6 7 8 9 10
if (out_file) { dup2(dev_null_fd, 0); } else { dup2(out_fd, 0); close(out_fd); }
将ctl_pipe的读端重定向到198文件描述符,将st_pipe的写端重定向到199文件描述符。
关闭原本打开的管道,并设置一系列的环境变量。调用
execve()启动target_file,实际上这个时候forkserver的代码已经被注入到target_file(在白盒模式下通过插桩,在黑盒模式下qemu中通过patch)。forkserver将被启动然后准备和fuzzer进行交互。
上面是对于fs逻辑,对于fuzzer来说同样需要一些处理。首先是对于两条管道,ctl_pipe的读端将被关闭,st_pipe的写端将被关闭。然后fuzzer开始等待forkserver启动,具体的做法是:
为fuzzer设置timer因为我们不希望fuzzer一直等下去。
- fuzzer调用read函数从st_pipe读端读取fs的状态,此时fuzzer将被阻塞住。
- 一旦读取到4个字节长度的数据,就代表fs已经准备好,
init_forkserver()将返回。
如果read没有成功读取4个字节的数据,那么接下来还有一系列逻辑去分析fs启动失败的原因:内存限制过小、timeout太短……
has_new_bits
这个函数的功能是计算bitmap在上次执行过后是否有变化。
在这个过程中需要使用一个virgin_bits这个bitmap表示在在整个执行过程中bitmap中没有被访问到的区域(通过对trace_bits取反在做与得到),没有被访问的字节的值位0xff。
它判断是否有变化产生的逻辑如下:
- 判断
trace_bits当前字节是否为0,为0代表这个块根本就没有被执行过。 - 判断当前字节(
classify_counts分类之后)和virgin_bits对应字节做与之后是否为0,如果为0代表没有发生变化。 - 如果上面两个条件都不为0,那么说明有变化产生。
接下来要判断的是产生的是哪种形式的变化?是有新的BB被执行还是,被执行的BB的执行次数发生了变化。只需要判断virgin_bits对应的字节是否为0xff(0xff代表从未被执行过),如果是0xff的话那么说明有新的块被执行,如果不是0xff那么说明只是执行此时发生了变化。最后更新virgin_bits。
然后根据对应的情况返回1或者2。
run_target
我们只讨论在有forkserver的情况下这个函数的执行逻辑。
这个函数将使用之前写入文件中的testcase作为输入运行target_file,并收集运行信息。
- 首先清空上一次测试留下的bitmap。
- 然后向ctrl_pipe中写入
prev_timed_out的4个字节(实际上在forkserver那边只是要求接收4个字节的数据并没有要求必须是prev_timed_out,这里不知道有什么特殊含义),指示forkserver可以启动fork子进程并开始测试。 - 在写入之后,fuzzer开始在st_pipe读端读取创建的子进程pid(也是四个字节),读到之后说明子进程已经启动成功。
- 为fuzzer设置timer,继续在st_pipe读端端读取子进程的结束状态status(由forkserver发送)。
- 在子进程结束之后对这一次运行过程中的得到的bitmap进行分类,然后根据status判断在这次的测试过程中是否有错误发生,如果有返回错误码,如果没有返回0。
每调用依次run_target都代表了使用testcase完成了一次测试。
update_bitmap_score
这个函数的作用实际上是为testcase打分,而选择出所有testcase中更优秀的部分并专注于使用这些更优秀的testcase进行fuzz。什么是更优秀的testcase呢?对于两个testcase来说,在能够覆盖到相同路径的情况下,谁的体积更小谁的执行时间更短就更优秀。
afl为bitmap代表的所有BB创建了另一个maptop_rated,top_rated是BB到testcase的映射,它代表了所有可以覆盖到这个BB的testcase中表现最优秀的testcase。
对于一个新的testcase来说:
- 在
update_bitmap_score中将遍历在使用这个testcase(t1)生成的bitmap的每一个字节,如果这个字节不为0那么说明这个testcase可以覆盖到这个BB。 那么函数将去top_rated中找到对应BB到现在为止最优秀的testcase(t_bset),并将t_best和t1的执行时间和大小的乘积作比较。如果t1的值更小那么t1将替代t_best成为这个BB上最好的testcase。
- 如果找到了更好的就将top_rated中对应的元素替换掉。
这样我们就可以专注于使用更好的testcase去测试。
cull_queue
这个函数在工作过程中一共使用两个数组:top_rated和temp_v:
- top_rated:保存的是对于每个可以覆盖到的BB来说最优秀的testcase。
- temp_v:代表的是到精简过程中的一刻为止,队列中所有可以被覆盖的BB。
首先在精简之前清空队列中所有testcase的favored标志位,这个标志位表示testcase是被保留的。
遍历所有的BB,如果这个BB的top_rated对应的testcase不为空,且temp_v中表示这个BB还不能被覆盖,那么表示fuzzer需要一个优秀的testcase来覆盖到这个BB。
- 于是这个testcase的favored标志位将被置位,表示在这个testcase不会被精简。如果这个testcase的
was_fuzzed标志位为0,那么意味着这个testcase还没有fuzz过,将pending_favored设置为1,表示有被筛选出的testcase还未被使用过。 - 除此之外,将在temp_v中将这个testcase所能覆盖的所有BB标记为0(表示可以覆盖)。
在完成遍历之后,将队列中所有favored没有被置位的testcase标志为冗余,并为其创建一个out_dir/queue/.state/redundant_edges/file_name这样格式的文件。
这个算法感觉还可以做一点改进:它每次选择到一个testcase之后不止将它最优秀的BB标记为已覆盖,它将这个testcase可以覆盖的BB都标记为已覆盖,这样对于其他BB来说更优秀的testcase就被屏蔽了,实际上在top_rated中每个BB都有它最优秀的testcase这些testcase都应该被保留XXD。
fuzz_one
跳过不感兴趣的testcase
在fuzz一开始先检查pending_favored标志位,确定是否有还未被fuzz的优秀的testcase。如果有的话可以考虑跳过一部分已经被fuzz过的或者不那么优秀的testcase:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
if (pending_favored) {
/* If we have any favored, non-fuzzed new arrivals in the queue,
possibly skip to them at the expense of already-fuzzed or non-favored
cases. */
if ((queue_cur->was_fuzzed || !queue_cur->favored) &&
UR(100) < SKIP_TO_NEW_PROB) return 1;
} else if (!dumb_mode && !queue_cur->favored && queued_paths > 10) {
/* Otherwise, still possibly skip non-favored cases, albeit less often.
The odds of skipping stuff are higher for already-fuzzed inputs and
lower for never-fuzzed entries. */
if (queue_cycle > 1 && !queue_cur->was_fuzzed) {
//%75 skip unfavored
if (UR(100) < SKIP_NFAV_NEW_PROB) return 1;
} else {
//%95 skip unfavored
if (UR(100) < SKIP_NFAV_OLD_PROB) return 1;
}
}
根据上面的源码看出来有三种跳过的策略:
- 如果有优秀的且尚未被fuzz过的testcase那么跳过其他99%被fuzz过的或者不那么优秀的fuzz。
- 如果没有上面那种条件很好的testcase,仍然存在跳过testcase的情况。当总testcase的数量大于10且当前的testcase不是优秀的,仍然有可能跳过当前的testcase去找到一个优秀的:
- 如果已经经过一轮fuzz且testcase还未被fuzz过那么有75%跳过这个不优秀的testcase。
- 否则有90%跳过这个不优秀的testcase。
在经过跳过阶段之后afl将打开当前testcase被保存的文件夹,然后调用mmap()将文件中的内容映射到内存中。
CALIBRATION
然后进入校准阶段。
对之前校准失败的testcase进行重新校准,只要失败次数不超过三次,那么就再为这个失败的testcase进行校准。但是校准之后只要当前模式不是crash mode,且返回的结果不是FAULT_CRASH,就仍然会跳过这个testcase即便它在这次校准中成功。所
这个校准阶段的含义我也不太明白,在官方文档上说这个部分的意义是:一个预模糊阶段,检查执行路径以检测异常,建立基线执行速度等。每当有新发现时执行非常短暂。(TODO:但是每个testcase不都已经经过校准了么?)根据对于校准结果的处理我怀疑:这次校准专门为crash mode服务,为crash mode获得获得最近一次的testcase的执行信息。
TRIMING
裁剪阶段,在官方文档中对这个阶段是这么描述的:另一个预模糊阶段,测试用例被修剪为仍然产生相同执行路径的最短形式。长度 (L) 和步距 (S) 的选择通常与文件大小有关。
在这个阶段调用trim_case()对testcase进行修剪。修剪的逻辑就是:
- 根据testcase的长度确定第一次修建的长度同时也是步距(L)和开始的位置(SP)。
- 然后将testcase从SP开始的L个字节剪掉,重新写回out_file。
- 然后调用
run_target()用新的testcase测试程序,然后计算覆盖率hash。- 如果hash值没有变化,那么说明覆盖路径没有变。将这一段从testcase中永远删去并写回testcase原文件。然后仍然从这个SP开始修剪,直到剪到SP大于testcase,或者路径开始发生变化。
- 如果hash值发生了变化,那么SP = SP + L,从新的SP位置尝试修剪,直到SP大于testcase的长度。
- 上面的两种情况迭代完之后,将L除以二再次进行上面的过程。
修剪完成之后,更新testcase的被保存的len和修剪标识符。
PERFORMANCE SCORE
对testcase打分。这个阶段主要是为havoc阶段做准备,为testcase所打上的分数将决定在havoc阶段对testcase处理的严重程度。打分主要根据:testcase的执行速度、testcase对应bitmap中被覆盖的大小、testcase被发现的轮数(到多少轮这个testcase才被发现)、testcase深度。
在以下情况下会跳过确定性变异直接跳转到havoc阶段:
- afl指定了-d参数,跳过确定性变异。
- 这个testcase已经经历过确定性变异(可能被中断了)。
- 这个testcase已经被fuzz过。
SIMPLE BITFLIP
进入bit翻转阶段。afl使用下面的宏进行bit的翻转:
1
2
3
4
5
#define FLIP_BIT(_ar, _b) do { \
u8* _arf = (u8*)(_ar); \
u32 _bf = (_b); \
_arf[(_bf) >> 3] ^= (128 >> ((_bf) & 7)); \
} while (0)
其中_ar是要被反转的testcase的指针,而_b指示的是要被反转的bit在testcase中的偏移。_b & 7就是要反转的那个bit在对应的那一字节中的偏移,而_b » 3正好是要翻转的那一字节在testcase中的偏移。这个宏的构思还是很巧妙地。
首先是1/1的翻转,即每次翻转一个bit然后前进一个bit。在翻转后调用common_fuzz_stuff()用变异后的testcase测试程序,再将对应的字节翻转回来,然后再进行下一个字节。
这个阶段除了有翻转位fuzz的任务之外,这个阶段还负责从testcase中自动截取token,并在之后的阶段使用。对于xxxxspecxxx这样的一个testcase来说,假如spec是一个token,它是这个testcase的中的关键词。afl提取token逻辑是:改变spec单词中中任何一个字节,将导致执行路径产生相同的执行路径,但这些执行路径与改变其他字节所产生的完全不同。这样就标识spec是一个关键词一样的存在。而afl选择将这个阶段放在在翻转每个字节的最后一位时去完成统计,因为在这个阶段对testcase产生的变异比较轻微所以更容易实现判断的的逻辑。
然后是2/1的翻转,每次翻转2个bit然后前进1个bit。测试的逻辑和1/1相同只是没有了对于token的截取。
然后是4/1的翻转,每次翻转4个bit然后前进1个bit。
再然后是8/8的翻转,每次翻转一个字节然后前进一个字节。在这个阶段也有任务就是effector map的构建,effector map在构建完成之后一直存在于deterministic fuzzing过程中。它构建的逻辑是这样的:在testcase中如果一个字节被翻转之后执行情况还是和翻转之前一样,那么说明这个字节可能不是testcase中的meta data,它只是一些无关紧要的数据,所以在以后的确定性变异中会参考effector map跳过这些字节,节省时间。
sakura师傅说的太好了:由此,通过极小的开销(没有增加额外的执行次数),AFL又一次对文件格式进行了启发式的判断。看到这里,不得不叹服于AFL实现上的精妙。
但是effector map的设置也是有例外的,首先如果文件大小太小,或者是处于哑模式那么就不用标记了,所有的字节都被标记为有效。另外如果在标记完成之后发现整个map中有90%都被标记为有效,那直接将整个map标记为有效就可以了。
然后是16/8的翻转,每次翻转两个字节然后前进一个字节。和之前的翻转测试不同的是在翻转之前会先检查effector map中那两个字节是否是有效的,如果是有效的才会继续翻转测试,如果不是有效的就跳过了。
最后是32/8的翻转,逻辑和16/8的翻转逻辑一样。
然后BITFLIP阶段结束。
ARITHMETIC
在这个阶段fuzzer将对testcase中的数据进行加减运算类型的变异,并将变异后的结果用于测试。
首先是8/8的加减,也就是每次对一个字节进行加减运算,然后前进一个字节。
- 在变异前首先会检查在
effector map中即将被变异的字节是否有效,如果有效就开始变异。 - 在变异完成后检查变异之后的字节是否和之前翻转的字节有重复,如果有重复就跳过这一次变异。
- 变异的过程就是对数据进行加法和减法,加减的值为1…35,data + 1测试完之后测试data - 1这样直到35。而对于多字节数据来说,afl在加减过程中还考虑了大端和小端序,一般先进行小端的变异之后将数据翻转进行大端的变异。上面的每种变异都会被测试。
然后是16/8的加减,每次对两个字节进行加减运算,然后前进一个字节。
再然后是32/8的加减,每次对4个字节进行加减运算,然后前进一个字节。
INTERESTING
这个阶段fuzzer将对testcase中的数据进行替换,将替换后的testcase用于测试。
首先是8/8的替换,每次替换1个字节,然后前进1个字节。
和前面的变异一样,在替换之前总是先检查
effector map中即将被变异的字节是否有效,如果有效的话才会进行变异。而且afl并不只是简单的替换掉testcase中的内容,在替换之前它会检查这一次替换的结果能否由其他的变异方式所得到,如果可以的话,afl就会跳过这一次的变异。
而替换的内容是硬编码在afl中的,是一些作者总结出的可能会导致崩溃的数据:
1 2 3
static s8 interesting_8[] = { INTERESTING_8 }; static s16 interesting_16[] = { INTERESTING_8, INTERESTING_16 }; static s32 interesting_32[] = { INTERESTING_8, INTERESTING_16, INTERESTING_32 };
然后是16/8的替换,每次替换2个字节,前进一个字节。
最后是32/8的替换,每次替换4个字节,前进一个字节。
DICTIONARY STUFF
在这个阶段fuzzer将使用从字典中导入的token或者自动获取的token,对testcase中的内容进行覆盖或者插入到testcase中以获得变异样本。
user extras (over)
第一部分是先使用从字典中导入的token,使用这些token覆盖掉testcase中的原本的内容。覆盖的策略:对于每个token来说,从testcase的开头开始,覆盖掉后面的内容,然后向后移动一个字节,直到testcase中剩余的字节不够token使用为止。
在变异之前还是需要做一些检查:
- 首先检查,token的个数,如果token的个数过多那么直接跳过这个环节。
- 然后检查剩余字节的长度够不够token。
- 最后检查剩余的字节是不是和token重复,且检查
effector map确定剩余的字节是不是有用的。
然后变异生成样本测试。
user extras (insert)
这个部分还是使用字典导入的token,将这些token插入到testcase原本的内容中。在插入前先检查,插入之后testcase的长度是否超过了最大的长度MAX_FILE。
auto extras (over)
最后一部分是先使用从字典中导入的token,使用这些token覆盖掉testcase中的原本的内容。这个部分和user extras (over)的策略是一样的,唯一不同的就是在检查的过程中缺少了检查token数量。
HAVOC
上面所有针对于testcase的编译都是有规律的确定性的,而HAVOC则是充满随机性的变异,在这个过程中没人知道一轮将会发生哪些变异。
首先将根据在变异前为每个testcase所打的分数确定变异的轮数L1。HAVOC的循环分为两层,第一层是由L1决定的变异轮数,第二层是由L2决定的在一轮变异中要进行的操作。而L2是一个随机数,L2次随机操作组合起来形成一次变异。
而随机变异都包括:
- 随机翻转其中的一位。
- 随机使用interest8替换掉随机的一个字节。
- 随机选择大小端并且随机使用interest16替换掉其中的两个字节。
- 随机选择大小端并且随机使用interest16替换掉其中的四个字节。
- 随机对一个字节执行加法操作。
- 随机对一个字节执行减法操作。
- 随机选择大小端并对两个随机字节执行减法操作。
- 随机选择大小端并对两个随机字节执行减法操作。
- 随机选择大小端并对四个随机字节执行减法操作。
- 随机选择大小端并对四个随机字节执行减法操作。
- 随机选择一个字节将其设置为随机值。
- 随机删除一段testcase。
- 随机选取一个位置,插入一段随机长度的内容,其中75%的概率是插入原文中随机位置的内容,25%的概率是插入memset的一段随机选取的数。
- 随机选取一个位置,替换为一段随机长度的内容,其中75%的概率是替换成原文中随机位置的内容,25%的概率是memset成一段随机选取的数。
内层循环每次都会随机选择一个操作类型,然后一次变异会选择L2个这样的操作。经过这样的变异后,testcase中的内容就很难预测了。这样在确定性变异之后又添加的是HAVOC这样的随机变异。
splice
如果在fuzz一开始时发现前后两次fuzz没有导致队列中有新增的testcase,没有新的路径被发现。那么再一次的fuzz中就可能进入splice环节,也就是组合环节。
1
2
3
4
5
6
[ ... ]
if (use_splicing && splice_cycle++ < SPLICE_CYCLES &&
queued_paths > 1 && queue_cur->len > 1) {
[ splice ]
}
[ ... ]
在这个环节将挑选一个随机的testcase与当前的testcase进行组合产生新的testcase,而组合的位置是两个testcase出现不同的区域的随机一个位置,当然如果两个testcase完全相同那么就没必要组合。组合完成新的testcase将被在送到havoc阶段进行变异,然后进行测试。
上面这样的组合过程要进行15次才算结束。
有了组合、变异、和由覆盖率引导的筛选,就可以看出afl的整个算法和遗传算法是很一样的。
finish
在上面一系列的变异和测试完成之后,fuzz_one()函数就会退出,这样针对一个测试用例的fuzz过程就算结束了。
common_fuzz_stuff
首先这个函数检查post_handler是否为空,如果为空那么下一步。如果不为空调用post_handler(),并传入out_buf(其中保存了变异数据)和len(testcase长度),对test进行处理,这一步确实很有用处如果需要自定义一些对于testcase的处理那么就可以使用这个接口。而这个posthandler是可以通过动态链接库导入的。
然后将testcase写入outfile然后调用run_target()用这个testcase测试程序,然后根据测试结果来处理这个变异后的testcase。
如果返回的结果是FAULT_TMOUT那么检查连续超时的testcase数量,如果小于250个那么可以处理这个超时testcase,如果超过250个那就直接返回,表示丢弃这个变异testcase。
然后相应由用户发出的SIGUSR1信号跳过这个testcase。
最后调用save_if_interesting()对这个testcase进行可能的save操作。
save_if_interesting
讨论下在非crash mode之下的工作。
在测试返回no_fault的情况下,首先调用has_new_bits()检测是否有新的BB被覆盖或者是否有BB的执行次数增加,如果没有那么直接返回,表示这一次变异没有价值可以舍弃。
如果有执行情况发生变化,为新testcase创建保存的文件:out_dir/queue/id:paths,调用add_to_queue()将变异后的testcase加入队列中。并将新testcase的has_new_cov置位,queued_with_cov++。在加入队列之后,调用calibrate_case()对testcase进行校准。完成校准之后将testcase写回到文件中。
如果测试时发生错误(那说明有问题太棒了!)。
对于超时错误,afl也没有选择全部舍弃,而是选择保存一部分(500个测试用例)测试用例。先调用
simplify_trace()简化bitmap,之后调用has_new_bits()检查是否有新的BB被覆盖(相对于所有的timeout cases来说)。如果没有就直接舍弃了。如果有的话,用一个更宽松的timeout(hang_tmout)再次测试整个程序,有三种情况:- 第一种仍然返回timeout那么afl有理由相信在这个testcase下,程序应该是阻塞住或者挂起了。
- 第二种返回的是crash,那么说明是执行时间不够,实际上应该是crash,所以跳转到crash的情况。
- 第三种返回的是其他任意一种情况,那么就舍弃这个testcase。
如果第二次测试是第一种情况,那么保留这个testcase:在crash目录为,testcase创建文件并写回。但是并不加入到队列中。
如果发生了crash那我们更开心了,但是并不是所有的crash都被保存(可能存在一些重复的crash),afl只保存相对于以前的crash里有新的BB被覆盖的,且只保存5000个。
这样在经历了这个函数之后所有的我们感兴趣的testcase都将被收集起来:所有导致新的执行情况但未崩溃的testcase将被加入到队列中,而所有覆盖了新的BB的崩溃的testcase将被保存到崩溃的文件夹中。
fuzzer与forkserver间的通讯机制和桩代码
forkserver
https://www.cnblogs.com/hac425/p/11614235.html
afl为了加快fuzz的效率而选择使用forkserver机制,首先来总结一下afl是如何实现forkserver(fs)和fs怎么帮助afl加快fuzz效率。
fs实际上并不是一个独立的server,在白盒模式下使用afl-as将fs的代码调用嵌入到被测试程序的每一个基本块中;而在qemu模式下fs的代码被直接添加到qemu中。所以fs实际上是被测试程序或者qemu的一部分。
所以afl在init_forksever()中fork一个子进程并运行fs,实际上就是运行一个target_file或者运行qemu解释执行目target_file,而在target_file运行之前将会调用fs的逻辑和fuzzer进行通信。
因为白盒模式下fs的代码是以汇编的形式给出的,所以对于fs逻辑的分析使用的是qemu mode下的c代码,这两个的逻辑是差不多的。在qemu中调用cpu_tb_exec()解释执行每个基本块,而对于fs的调用就被嵌在这个函数的开头:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
static inline tcg_target_ulong cpu_tb_exec(CPUState *cpu, TranslationBlock *itb)
{
CPUArchState *env = cpu->env_ptr;
uintptr_t ret;
TranslationBlock *last_tb;
int tb_exit;
uint8_t *tb_ptr = itb->tc_ptr;
AFL_QEMU_CPU_SNIPPET2;//!!!!!
qemu_log_mask_and_addr(CPU_LOG_EXEC, itb->pc,
"Trace %p [%d: " TARGET_FMT_lx "] %s\n",
itb->tc_ptr, cpu->cpu_index, itb->pc,
lookup_symbol(itb->pc));
[ ... ]
}
#define AFL_QEMU_CPU_SNIPPET2 do { \
if(itb->pc == afl_entry_point) { \
afl_setup(); \
afl_forkserver(cpu); \
} \
afl_maybe_log(itb->pc); \
} while (0)
在执行一个基本块前首先判断这个基本块是不是一个程序的入口,如果是的话进入fs的逻辑,调用afl_setup()(这部分和白盒模式下的逻辑不太一样,在白盒没有检查这个BB是否是入口BB,而是通过判断共享内存的地址是否为NULL,来确定是否进入fs逻辑):
- 从环境变量
AFL_INST_RATIO中获得统计代码覆盖率的百分比,也就是说在设置这个环境变量的情况下只有一部分BB的执行情况会被统计,这适用于测试非常大的程序。 - 然后从环境变量
__AFL_SHM_ID中获得共享内存的文件描述符,并将共享内存添加到qemu的内存空间。
初始化工作完成后,调用afl_forkserver()开始和fuzzer通信,下面是fuzzer和fs间通信的协议:
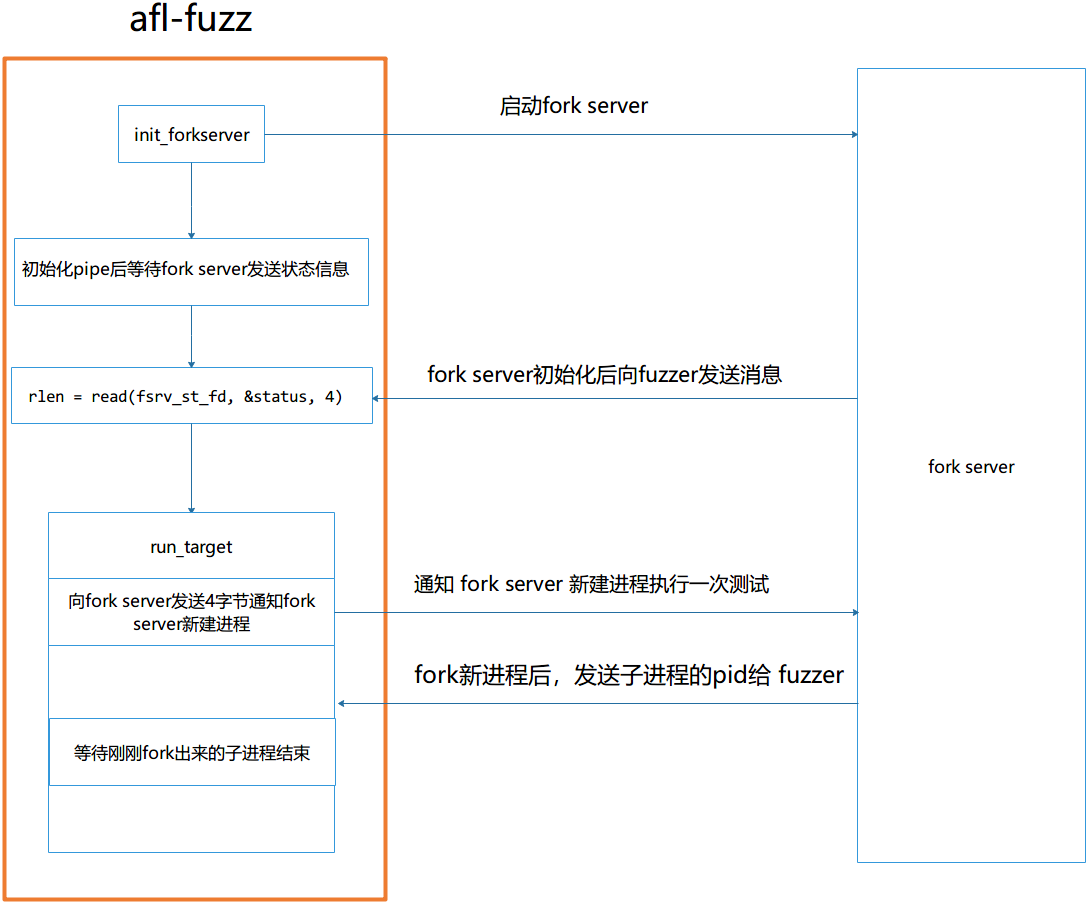
因为这个时候fuzzer还在等着fs相应,所以先通过st_pipe的写端向fuzzer发送四个字节的响应信息通知fuzzer fs已经启动完成,让fuzzer继续下面的工作。
然后fs进入一个循环中,开始从ctrl_pipe的读端读取fuzzer的控制信息,这个时候fs将会阻塞在这个位置。一旦接收到fuzzer发送的四个字节控制信息,fs将会fork一个新的进程作为被测试程序。此时fs和被测试进程将有不同的执行路径:
1 2 3 4 5 6 7 8 9
if (read(FORKSRV_FD, tmp, 4) != 4) exit(2); /* Establish a channel with child to grab translation commands. We'll read from t_fd[0], child will write to TSL_FD. */ if (pipe(t_fd) || dup2(t_fd[1], TSL_FD) < 0) exit(3); close(t_fd[1]); child_pid = fork();
fs:通过st_pipe的写端将新进程的pid发送给fuzzer,然后调用
afl_wait_tsl()函数(这个函数的作用下面再详细介绍)。被测试进程:关闭一系列fs的管道,然后从fs中返回。
1 2 3 4 5 6 7 8 9 10 11
if (!child_pid) { /* Child process. Close descriptors and run free. */ afl_fork_child = 1; close(FORKSRV_FD); close(FORKSRV_FD + 1); close(t_fd[0]); return; }
- 白盒:开始执行二进制文件的正常逻辑。
- 黑盒:返回到qemu开始对程序进行正常的翻译执行。
再接下来被测试进程将会正常执行,并根据每个BB的桩代码将代码覆盖率写入共享内存中。fs在执行完
afl_wait_tsl()之后会调用wait()等待被测试进程的退出,然后将退出代码通过st_pipe发送给fuzszer,然后开始下一次迭代。1 2 3 4 5 6 7 8 9 10
if (write(FORKSRV_FD + 1, &child_pid, 4) != 4) exit(5); /* Collect translation requests until child dies and closes the pipe. */ afl_wait_tsl(cpu, t_fd[0]); /* Get and relay exit status to parent. */ if (waitpid(child_pid, &status, 0) < 0) exit(6); if (write(FORKSRV_FD + 1, &status, 4) != 4) exit(7);
上面是整个fs和fuzzer之间的通讯过程,和fs的工作原理。
afl将被测试程序当作是forkserver,fs将在main函数的第一个基本块被read()阻塞住,每当从fuzzer获得一次通知才fork出一个子进程并继续执行正常逻辑,这样的设计可以避免在每次执行被测试程序时调用execve()来加载进程,也避免了一些动态库加载等等的初始化工作,每次被测试程序都将直接从main函数开始执行,这样可以很大程度提高fuzz的效率。对于qemu mode也是如此。
桩代码
上面已经介绍过一部分forkserver的桩代码了,fs部分的桩代码只有在第一次被fork的fs子进程的main函数的第一个BB中被调用,后续通过fs所fork出的孙进程中是不会调用fs部分的桩代码的(只有一个fs),因为孙进程的共享内存地址不为NULL(在fs中被初始化)。但是其他部分是会被正常调用。还是以qemu mode为例子。
qemu在翻译每个BB前都会调用afl_maybe_log()用于统计代码覆盖率。
在这个函数中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
static inline void afl_maybe_log(abi_ulong cur_loc) { static __thread abi_ulong prev_loc; /* Optimize for cur_loc > afl_end_code, which is the most likely case on Linux systems. */ if (cur_loc > afl_end_code || cur_loc < afl_start_code || !afl_area_ptr) return; /* Looks like QEMU always maps to fixed locations, so ASAN is not a concern. Phew. But instruction addresses may be aligned. Let's mangle the value to get something quasi-uniform. */ cur_loc = (cur_loc >> 4) ^ (cur_loc << 8); cur_loc &= MAP_SIZE - 1; /* Implement probabilistic instrumentation by looking at scrambled block address. This keeps the instrumented locations stable across runs. */ if (cur_loc >= afl_inst_rms) return; afl_area_ptr[cur_loc ^ prev_loc]++; prev_loc = cur_loc >> 1; }
- 首先会获取当前qemu翻译执行的地址。
- 然后对这个地址cur_loc取hash(注释里对于这一点的描述是因为指令会有对齐的情况存在,所以需要取hash让地址更加均匀)。
- 最后将cur_loc和prev_loc异或之后(这个异或应该是为了统计从不同地C址跳转到这个BB的多种情况)的值作为访问bitmap的索引,将bitmap中对应的值加一。
然后将prev_loc赋值为cur_loc » 1。
cache相关桩代码
上面是白盒模式和qemu mode下都会有的统计代码覆盖情况的桩代码。除此之外在qemu mode下还有用于加快qemu执行速度的桩代码。
qemu在执行机器码之前会先将机器码翻译成一种qemu定义的中间表示然后再解释执行,而qemu为了加快翻译执行的速度引入了cache机制。前面说过fs在fork新进程之后会调用afl_wait_tsl(),这个函数的功能就是fs从子进程获得翻译块。
当qemu调用cpu_tb_exec()翻译执行二进制程序时,会先从cache中查看是否能找到要执行的BB,如果可以找到就直接从cahce中加载出来解释执行。如果在cache中找不到这个BB就需要先将这个BBB翻译成IR,再去执行,同时这个BB也将被保存在cahce中。
afl_wait_tsl()的逻辑是:在qemu为被测试进程翻译BB时同时调用 afl_request_tsl()将这个BB的信息发送给fs,fs也是一个qemu进程,fs将检查这个BB是否保存在自己的cache里,如果没有的话fs将翻译这个BB,并将翻译后的BB加入到cache中。这样再从fs中fork出来的自己成的cache中就保存了运行需要的BB,省去了翻译的时间,加快了执行效率。
AFL LLVM mode
和afl-gcc不同,在这个模式下afl使用llvm pass在每个BB前插桩,这样准确率更高。
detail:TODO
conclusion
在经历过几年时间的迭代,afl汇聚了世界各地的fuzzing大聪明的研究成果,它的内部实现非常精妙。
如果想要在短时间内写出一个可以媲美afl的基于变异的灰盒fuzz框架,难度还是挺大的,但是可以从变异策略、引导策略的方向做改进。
接下来感觉还需要去读一些读论文,了解现在对于fuzz的改进方法。